背景
对于比较关键的下单接口,性能直接影响到商户的使用体验。目前,我们的下单接口大部分耗时都在4s-5s之间,少数耗时在2-3s。具体耗时多少,也和实际覆盖到的流程有关,不同分支流程,需要处理的业务逻辑往往不一样,调用接口数量也不一样。
思路
4s-5s耗时算比较多的,考虑到有些商户网络比较差,客户端从下单到接收到返回数据的实际耗时会更多,实际体验也会更差。
缩减耗时,可以从mysql优化入手,但是我们的sql已经挺快了(我的意思是,它的优化空间并不是很大,继续优化的难度会越来越大),网络耗时的优化也难以有很明显的效果。
从ztrace的监控面板上可以看到,几乎所有请求都是串联的,只要改为并发,就可以大大减小接口总耗时。这么多的接口,只要拿5、6个做并发,就可以节省接近1s的时间,所有优化空间很大。
特别是一些诸如“获取用户信息”、“获取商户信息”、“获取商品信息”之类的接口,它们对执行顺序没有特别要求,完全可以在接口开始时就做并发。
调用链跟踪系统的一个巨大优点就是直观,每个部分的耗时都可以显示出来,并且进行对比。
操刀
PHP有对并发访问的支持:curl_multi_init,但是要用到我们项目里,要尽量减小对原流程的干涉,所以做了一些独特的设计。
cURL批处理的用法,是先初始化一个批处理句柄:
curl_multi_init,然后通过curl_multi_add_handle把普通的curl句柄加入批处理句柄,再统一执行(并发)。
下面是一个例子,来自:php.net
<?php
// 创建一对cURL资源
$ch1 = curl_init();
$ch2 = curl_init();
// 设置URL和相应的选项
curl_setopt($ch1, CURLOPT_URL, "http://www.example.com/");
curl_setopt($ch1, CURLOPT_HEADER, 0);
curl_setopt($ch2, CURLOPT_URL, "http://www.php.net/");
curl_setopt($ch2, CURLOPT_HEADER, 0);
// 创建批处理cURL句柄
$mh = curl_multi_init();
// 增加2个句柄
curl_multi_add_handle($mh,$ch1);
curl_multi_add_handle($mh,$ch2);
$running=null;
// 执行批处理句柄
do {
usleep(10000);
curl_multi_exec($mh,$running);
} while ($running > 0);
// 关闭全部句柄
curl_multi_remove_handle($mh, $ch1);
curl_multi_remove_handle($mh, $ch2);
curl_multi_close($mh);
?>
我直接找了一个相关库,并把它clone到了公司github上,保留了授权(感谢Apache License,感谢作者,附上原地址:jmathai/php-multi-curl,内部项目地址:shop/php-multi-curl)
为了少改业务流程,我设计了一个方法:preExec,它的参数和execApi一样。
它的作用是生成请求的curl句柄,并将其加入到批处理(还没执行),然后计算请求的hash,设置$ci->preExec[$request_hash](可以通过它去获取这次请求的结果)。
如何计算请求hash:请求hash的计算元素,包括请求url、请求params、请求method。
function requestHash($url, $p, $method)
{
$url = strtolower(trim(trim($url), '&?/\\'));
$phash = $this->arrayHash($p);
$method = strtolower(trim($method)) == 'post' ? 'post' : 'get';
return md5($url . $phash . $method);
}
function arrayHash($p, $filter = array('mdstr', 'expire'))
{
$para_sort = array();
foreach ($p as $k => $v) {
if ($filter && in_array($v, $filter, true)) continue;
// array object bool int float null resource...
$para_sort[$k] = is_array($v) ? $this->arrayHash($v)
: (is_object($v) ? $this->arrayHash((array)$v) : strval($v));
}
ksort($para_sort);
return md5(http_build_query($para_sort));
}
当我们去主动获取请求结果时,如果当前请求已经执行完成,会立即返回请求结果,其他还没执行完的请求继续执行,不堵塞业务流程。如果当前请求没执行完,会堵塞直到当前请求执行结束。
执行execApi时,先判断是否有设置$ci->preExec[$request_hash],如果没设置,就是一次普通的curl访问,和以前的流程一样(单次请求,堵塞直到获取到结果);如果有设置,那就执行curl批处理(所有的并发请求都在这时开始执行。如果已经执行过了就不再执行),并通过$ci->preExec[$request_hash]去获取当前请求的结果。获取到结果后,会将$ci->preExec[$request_hash]删除。
所以,只要我们在流程开始前执行preExec,那执行到execApi的时候就会自动做并发,并获取结果。
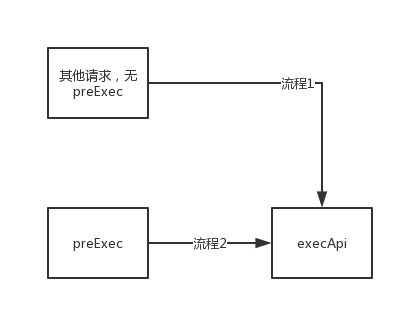
在流程1和流程2,execApi分别执行普通curl访问、并发curl访问。
DEBUG流程
下面讲一些遇到的坑。
开始做并发时很顺利,也成功实现了并发。但是当我把它和调用链跟踪结合起来的时候,一大堆问题就来了。
为了准确跟踪接口调用时间,我们需要记录每个curl的执行开始时刻,和执行过程的耗时。
每创建一个curl句柄后,我们都会向curl批处理会话中添加这个单独的curl句柄,但是这个时候curl是没开始执行的。如果我们把创建curl的时刻作为url开始访问的时刻,记录到的接口生命周期会比实际的长很多(提前记录了)。
这时我想到了通过记录curl结束时间和curl耗时,反推开始时间。而curl有个回调函数,可以在接收到数据的时候执行:
CURLOPT_WRITEFUNCTION(有没有curl开始执行的回调函数呢?很遗憾没有!)
于是,我使用了CURLOPT_WRITEFUNCTION来记录curl调用的结束时刻。但是在235上,设置CURLOPT_WRITEFUNCTION后总是得不到返回数据(curl_exec总是返回TRUE),我发现CURLOPT_RETURNTRANSFER设置失效了!
** 235上的libcurl版本是:7.19.7**
CURLOPT_WRITEFUNCTION 回调函数名。该函数应接受两个参数。第一个是 cURL resource;第二个是要写入的数据字符串。数 据必须在函数中被保存。 函数必须准确返回写入数据的字节数,否则传输会被一个错误所中 断。
CURLOPT_RETURNTRANSFER TRUE 将curl_exec()获取的信息以字符串返回,而不是直接输出。
一顿折腾,在Stack Overflow上找到一点提示 ready go
When I placed that line before any of the other options, it was simply ignored.
我尝试在设置CURLOPT_WRITEFUNCTION后再次设置CURLOPT_RETURNTRANSFER,这次跑通了。
BUT!我自己的电脑上又出问题了,设置了CURLOPT_WRITEFUNCTION,CURLOPT_RETURNTRANSFER就失效,CURLOPT_RETURNTRANSFER生效的时候,就不执行CURLOPT_WRITEFUNCTION。在需要二选一的时候,我选择了放弃。
** 我电脑上的libcurl版本是:7.55.0**
我放弃了CURLOPT_WRITEFUNCTION。找到了一个替代回调函数CURLOPT_HEADERFUNCTION,这个函数会在接收到返回的header信息时调用。虽然它不能精确表示结束时间,但是马马虎虎也能用。最重要的是,这个函数始终都会被调用。
CURLOPT_HEADERFUNCTION 设置一个回调函数,这个函数有两个参数,第一个是cURL的资源句柄,第二个是输出的 header 数据。header数据的输出必须依赖这个函数,返回已写入的数据大小。
这时,调用链跟踪和并发成功结合起来了,监控的数据基本正确,也能正常运行。
如果看到ztrace上面,一个并发前只需要100ms+的接口,在并发后要800ms+,请相信我,curl_getinfo($ch, CURLINFO_TOTAL_TIME)返回的就是这个值,不是程序有bug。具体原因期待大神解释。
调试过程中还遇到一个libcurl的bug,这个bug只在 7.55.0 上有(没错,我电脑上的就是这个版本:broken_heart:)。这个bug就是curl_getinfo($ch, CURLINFO_TOTAL_TIME)会在某些时候返回一个超大的浮点数,比如4295.xx。而经过我观察,只需要减掉4295就行了(究竟对不对,就看我猜的对不对了:pray:)
结语
好了,上面是修改ApiShopClient的整个过程,主要时间花在了适配调用链跟踪上面,从这个debug流程也能看到,php在涉及到底层的时候有点力不从心(大神忽略掉这句)。