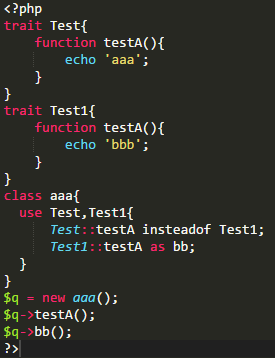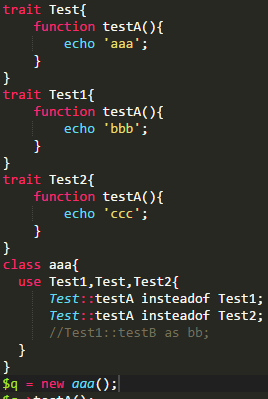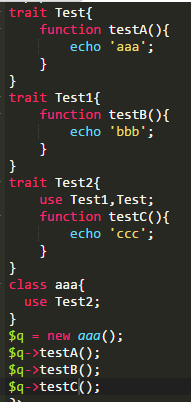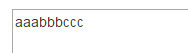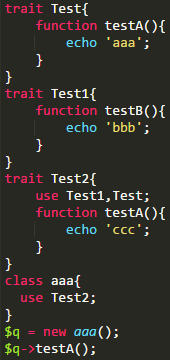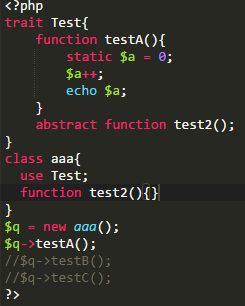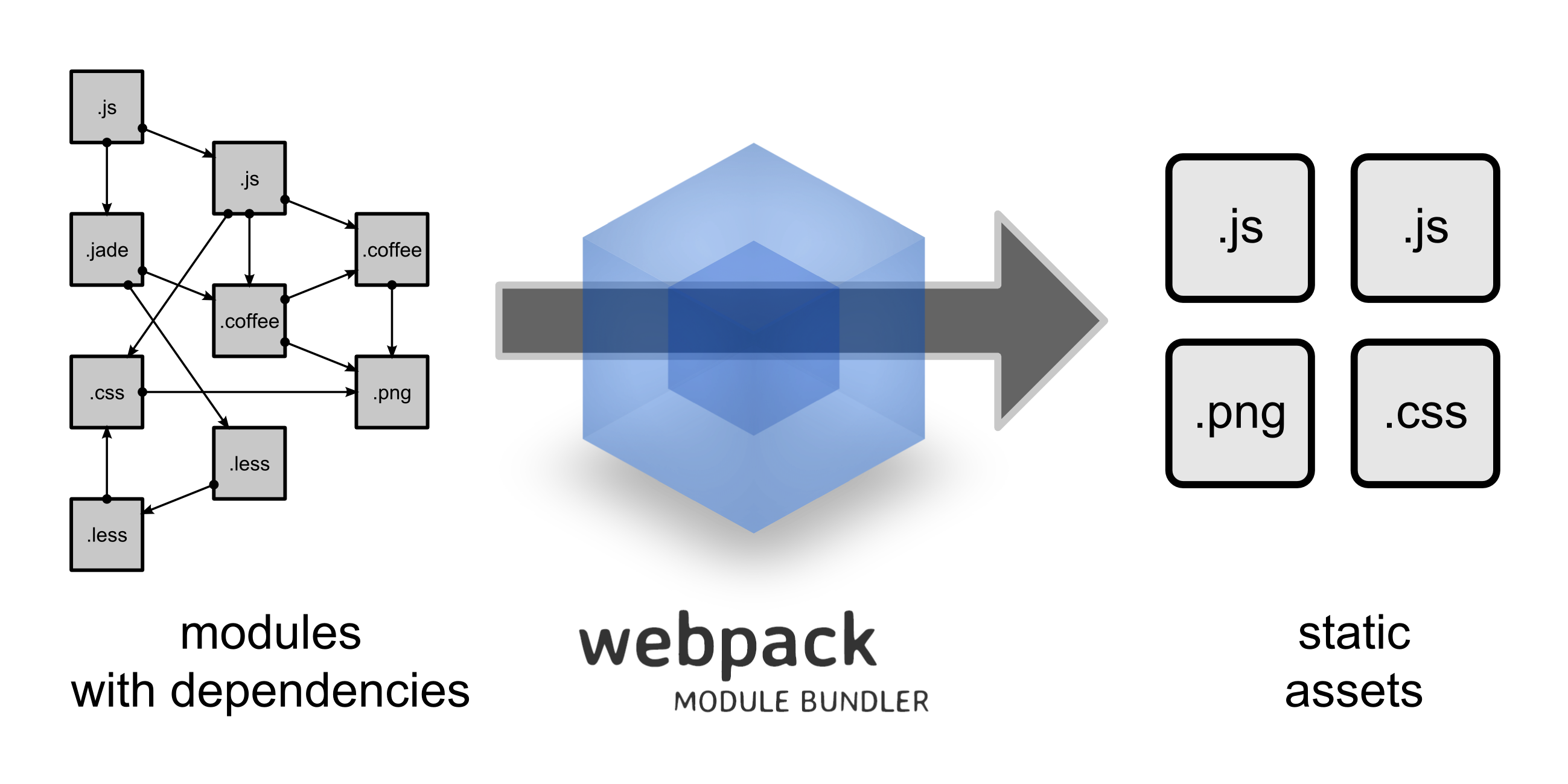
使用的DEMO
介绍
模块打包工具(不仅仅只是打包js)
模块
现在的网站都在演变成为Web Apps:
- 页面上的JavaScript越来越多。
- 在现代浏览器上用户可以做更多的事情了。
- 整个页面重新加载的情况更少了,与此同时,页面上的代码量更大了。
结果就是:客户端的代码量变得越来越庞大,庞大的代码量意味着我们需要适当地组织代码,而模块系统则提供了把代码分割成不同模块的功能。
模块化历史进程
- Script标签形式
- CommonJS(CMD)
- AMD和一些变种实现
- ES6模块
- 其它
目的
- 把依赖树按需分割
- 把初始加载时间控制在较低的水平
- 每个静态资源都应该能成为一个模块
- 能把第三方库继承到项目里来成为一个模块
- 能定制模块打包器的每个部分
- 能适用于大型项目
简单使用
几个名称
1. node
js的服务端实现,基于CMD
-
npm
> node 官方认证的包管理工具,类似于php composer。非常慢(加上代理也是慢)。
-
cnpm
> 阿里巴巴出品的包管理工具,兼容大部分npm功能,使用淘宝源,项目结构必npm简单,更新安装新的依赖快。
-
yarn
> facebook 出品的包管理工具,和cnpm类似,诞生时间多,但是比cnpm热,中国码农的国际影响力不行啊,有好东西不知道宣传,cnpm比yarn不知道早多久了。yarn 比cnpm突出的一点是:默认使用lock文件,固定版本,有利于大型项目规定依赖版本。
推荐使用yarn(不过cnpm更简单一些,所以可以先用cnpm)
npm install -g cnpm --registry=https://registry.npm.taobao.org
安装Webpack-cli
cnpm install webpack -g
使用命令行
// 最简单的命令 webpack <entry> <output>
webpack ./app.js bundle.js
额外参数
-p 压缩js并且丑化--watch 监控文件改动--progress 显示构建的详细过程
详细参数文档
使用配置文件
对于一般的项目,直接使用cli是不太可能的,所以我们需要配置文件,使用配置文件有两种方式
- cli
- node api
CLI
创建 webpack.config.js 文件
module.exports = {
entry: './src/app.js',
output: {
path: './dist',
filename: 'app.bundle.js'
}
};
然后在webpack.config.js文件的目录下面执行命令webpack
webpack 会自动查找目录下面的webpack.config.js,如果需要指定,可以使用--config 指定配置文件。
NODE API
创建webpack.node.js文件
var webpack = require("webpack");
webpack({
entry: './src/app.js', // 原文件
output: {
path: './dist', // 输出路径
filename: 'app.bundle.js' // 输出文件名
}
}, function (err, stats) {
});
然后在webpack.config.js文件的目录下面执行命令node webpack.node.js
DEMO2
ES6
一个很好的ES6指南
为什么要ES6?随波逐流是个好选择,不过就自己来说我喜欢ES6的这几个方面
- module管理,import和export使用非常爽
- let不自动扩展作用域
- =>,解决了function this的问题
下面我们使用ES6的module管理来编写一段程序
log.js
var log = function (text) {
console.log(text);
}
export {log};
app.js
var log = function (text) {
console.log(text);
};
export log;
不过es6现在不是浏览器的主流支持版本,所以需要转义成es5,这里就需要使用babel
修改package.json,加入babel依赖
{
"name": "webpack-demo",
"version": "0.0.1",
"scripts": {
"build": "webpack"
},
"devDependencies": {
"webpack": "^1.14.0",
"babel-core": "^6.18.2",
"babel-loader": "^6.2.8",
"babel-plugin-transform-runtime": "^6.15.0",
"babel-polyfill": "^6.16.0",
"babel-preset-es2015": "^6.18.0",
"babel-preset-stage-2": "^6.18.0"
}
}
再修改webpack.config.js
module.exports = {
entry: './src/app.js',
output: {
path: './dist',
filename: 'app.bundle.js'
},
module: {
loaders: [
{
test: /\.js$/,
exclude: /(node_modules|bower_components)/,
loader: 'babel-loader?cacheDirectory=true'
}
]
}
};
这里使用了webpack的loader功能,这是webpack最重要的功能了,加载各个模块,打包到指定的地方。
之后我们还需要指定babel使用的规范,这里有两个选择,一个是写在webpack的config文件中,还有一个是在root dir下面创建.babelrc来指定规范,这里选择第二种(因为这样可以确保别人能一眼看出你代码书写的规范),在当前目录创建.babelrc
{
"presets": ["es2015", "stage-2"],
"plugins": ["transform-runtime"],
"comments": false
}
然后在webpack.config.js文件的目录下面执行命令webpack
DEMO4
关于其他loader使用,一般是**-loader
- url-loader
- file-loader
- style-loader
- vue-loader
不过每个loader都存在一些使用的差异性,需要去查看各自的文档。
插件
之前可以使用webpack -p 压缩并且丑化js,不过在配置文件可以更详细的配置这些操作
module.exports = {
entry: './src/app.js',
output: {
path: './dist',
filename: 'app.bundle.js'
},
module: {
loaders: [
{
test: /\.js$/,
exclude: /(node_modules|bower_components)/,
loader: 'babel-loader'
}
]
},
plugins: [
// 压缩代码
new webpack.optimize.UglifyJsPlugin({
compress: {
warnings: false
}
}),
// 删除重复的依赖
new webpack.optimize.DedupePlugin()
]
};
再使用webpack试试看
加入Vue
使用vue需要vue-loader这个依赖,修改package.json,这些依赖是必须要的,must!
{
"name": "webpack-demo",
"version": "0.0.1",
"scripts": {
"build": "webpack"
},
"devDependencies": {
"webpack": "^1.14.0",
"babel-core": "^6.18.2",
"babel-loader": "^6.2.8",
"babel-plugin-transform-runtime": "^6.15.0",
"babel-polyfill": "^6.16.0",
"babel-preset-es2015": "^6.18.0",
"babel-preset-stage-2": "^6.18.0",
"css-loader": "^0.25.0",
"file-loader": "^0.9.0",
"style-loader": "^0.13.0",
"url-loader": "^0.5.7",
"vue-html-loader": "^1.0.0",
"vue-loader": "^8.0.0",
"vue-style-loader": "^1.0.0",
"vue-template-compiler": "^2.1.0"
},
"dependencies": {
"vue": "2.*"
}
}
webpack.config.js
var webpack = require("webpack");
module.exports = {
entry: './src/main.js',
output: {
path: './dist',
publicPath: 'dist/',
filename: 'app.bundle.js'
},
module: {
loaders: [
{
test: /\.vue$/,
loader: 'vue-loader'
},
{
test: /\.js$/,
exclude: /(node_modules|bower_components)/,
loader: 'babel-loader'
},
{
test: /\.css$/,
loader: 'style-loader!css-loader'
},
{
test: /\.(eot|svg|ttf|woff|woff2)(\?\S*)?$/,
loader: 'file-loader?name=font/[hash:8].[ext]'
},
{
test: /\.(png|jpe?g|gif|svg)(\?\S*)?$/,
loader: 'file-loader?name=image/[hash:8].[ext]'
}
]
},
vue: {
loaders: {
js: 'babel?cacheDirectory=true'
}
},
resolve: {
alias: {
vue: 'vue/dist/vue.js'
}
},
plugins: [
// 压缩代码
new webpack.optimize.UglifyJsPlugin({
compress: {
warnings: false
}
}),
// 删除重复的依赖
new webpack.optimize.DedupePlugin()
]
};
执行webpack,为了查看具体效果,创建一个index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<div id="app"></div>
<script src="dist/app.bundle.js"></script>
</body>
</html>
浏览index.html查看具体效果吧
DMOE6
一个悲痛的消息!webpack1(就是上面的)被放弃了,现在官方推行webpack2(有一些配置的不同),据说可以减少打包文件的大小,具体还要看实际效果。
官方文档
更全面的DEMO