备注:
1、项目组长必须具备中级工程师及以上资格
2、助理项目经理及项目经理必须具备高级工程师及以上资格
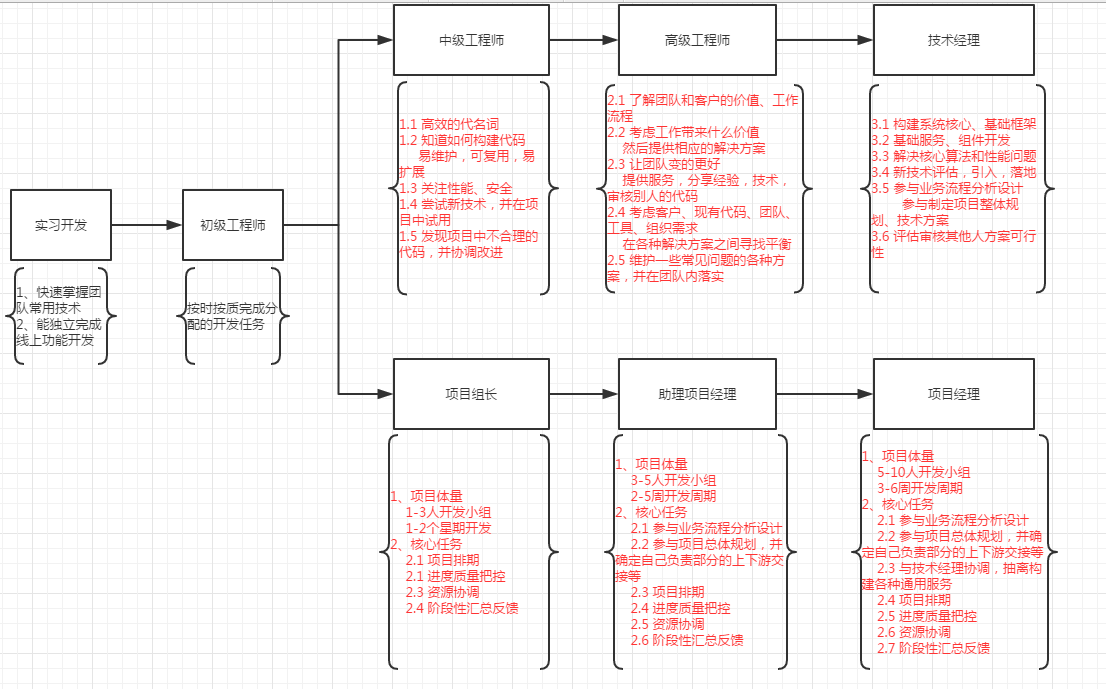
备注:
1、项目组长必须具备中级工程师及以上资格
2、助理项目经理及项目经理必须具备高级工程师及以上资格
编 写: zhangyue 日 期: 2017.1.6 说 明: 针对ajax页面的一些前进后退的处理
一 Ajax页面的特殊性
存在Ajax加载数据的页面,其url不会自动发生改变,除非通过手动更改url。此时,导致了当页面发生ajax加载的时候,页面url状态不会发生改变,后退页面时,会直接返回原始状态。
针对单页面应用,如果在A页面进行相关操作,然后跳转到B页面,此时再从B页面返回到A页面,A页面会重新加载,不会保持A页面之前进行的操作。
二 解决办法的过程
2.1 location.hash
通过location.hash调整地址栏的地址,使得浏览器里边的“前进”、“后退”按钮能正常使用,。然后再根据hash值的不同来显示不同的面板.
http://shopdev.ci123.com/svn/zydev/xinyi/category/itemlist/#sort=price&order=asc
#代表网页中的一个位置。其右面的字符,就是该位置的标识符
为网页位置指定标识符,有两个方法。一是使用锚点,比如,二是使用id属性。
#是用来指导浏览器动作的,对服务器端完全无用。所以,HTTP请求中不包括#。第一个#后面出现的任何字符,都会被浏览器解读为位置标识符。这意味着,这些字符都不会被发送到服务器端,改变#后的部分,不会重新加载网页。
每一次改变#后的部分,都会在浏览器的访问历史中增加一个记录,使用"后退"按钮,就可以回到上一个位置。这对于ajax应用程序特别有用,可以用不同的#值,表示不同的访问状态,然后向用户给出可以访问某个状态的链接。
window.location.hash这个属性可读可写。读取时,可以用来判断网页状态是否改变;写入时,则会在不重载网页的前提下,创造一条访问历史记录。
window.location.hash=value;
2.2 localStorage,SessionStorage
a.存储客户端临时信息的对象
b.localStorage生命周期是永久,这意味着除非用户显示在浏览器提供的UI上清除localStorage信息,否则这些信息将永远存在。
c.sessionStorage生命周期为当前窗口或标签页,一旦窗口或标签页被永久关闭了,那么所有通过sessionStorage存储的数据也就被清空了。
d.使用:
键值对方式储存值:
localStorage.key = v
localStorage['key'] = v
localStorage.setItem("key",v)
取值:
localStorage.key
localStorage.getItem("key");
清除:
localStorage.remove("key");
localStorage.clear();
通过localStorage或sessionStorage存储关键字段,当重新加载该页面的时候,检测,如果存在该字段,通过字段拼接,重新同过ajax请求加载数据;或者直接存储当前页面的某个元素的所有内容,重新加载该页面的时候,检测,如果存在值,则直接填充,无需再次去通过ajax请求
三 存在的问题
1 如果改变location.hash,那么会导致history增多,返回时,需要一步一步回退,不能直接返回原始界面,用户体验差。
2 可以考虑使用history的Api:
history.pushstate();//增加当前url history.replacestate();//替换当前url
进一步的可以参考:HTML5 操纵浏览器的历史记录history
3 后续完善版,可以参考: 移动端列表页操作优化
整 理:zhangyue 日 期:2017.1.6 说 明:关于js的this和事件冒泡等的部分总结
一 Js中this和Jquery中$(this)的区别
1.1 两者是不同的对象
$(this) :jquery对象
this:dom对象
1.2 dom对象和jquery对象的转换:
$(this)[0] == this;
var $argument=$("#argument"); //jquery对象
var argument = $argument[0]; //dom对象 也可写成 var argument=$argument.get(0);
var argument=document.getElementById("argument"); //dom对象
var $argument = $(argument); //转换成jquery对象
二 Js事件冒泡和事件委托
事件冒泡:子级元素的某个事件被触发,它的上级元素的该事件也被递归执行
事件委托:将子级元素的事件绑定在父级元素上;
对于动态生成的Dom元素,其事件绑定有两种方式:第一种,是在dom元素后生成的地方添加相应的绑定事件;第二种,将事件绑定在已经存在的父元素dom节点上。如果一开始就对该元素进行绑定事件,而该元素动态添加后,是不能够响应改绑定事件的。
//js 部分
createSonDom();
//第一种方式
$("#son").click(function(){
alert('son');
});
//第二种方式 事件委托
$("#parent").on('click', '#son', function() {
alert('son');
});
function createSonDom()
{
var tmp = [];
tmp.push('');
$("#parent").append(tmp);
//第三种方式
$("#son").click(function(){
alert('son');
});
}
第一种方式对于son元素无法响应,第二种可行,第三种可行。第三种存在缺陷,可能会导致事件多次响应
三 Js中this和event对比
js中事件是会冒泡的,所以this是可以变化的,
event.target不会变化,它永远是直接接受事件的目标DOM元素;
$(this)和event.currentTarget永远指向监听该事件发生的DOM元素;
event.target则是那个被点击的DOM元素.
四 使用this的冒泡问题解决
4.1 第一种:事件委托,不把事件绑定在自身元素上
4.2 off(),解除绑定事件,之后在进行绑定
$(this).off('click').on('click', function(){
alert('off');
});
4.2 使用event.stopPropagation()
能阻止父元素的click事件函数执行,但不阻止当前元素同时绑定的其它click事件函数执行
ps:event.preventDefault() 不组织冒泡事件,阻止默认行为
$('#son').on('click', function(event){
$(event.target).stopPropagation();//阻止事件冒泡
});
js类型的科普
1.js的值可以分为2种类型,基本类型和对象类型
2.基本类型包括:Undefined、Null、Boolean、Number和String等五种
3.其中Undefined类型和Null类型的都只有一个值,即undefined和null;Boolean类型有两个值:true和false;Number类型的值有很多很多;String类型的值理论上有无数个
类型转换图
ps:N表示tonumber转化为数字比较,P表示转为基本类型比较
多情况比较
一、有和无
1.如图所示,很显然,左边表示的都是确定的,有和非空的,而右侧就是不确定的,无,或者空的,很显然两者==作比较是false的
二、空和空
1.undefined和null是比较难以区分的点
首先我们看下两者的类型
alert(typeof undefined); //output "undefined"
alert(typeof null); //output "object"
前者很容易理解undefined的类型是undefined
后者你会想为什么null的类型是object有点无语,看别人解释是说这是一个最初设计的问题
alert(null == undefined); //output "true"
为什么会是true呢,null表示不存在对象,该出不应该有值
而undefined是该处缺少值,没有赋值
那如何区分两者呢(1.===;2.根据类型比较)
三、真与假
Boolean类型的值,与其他值作比较的时候,会转化为1和0
四、字符的序列
string和number分在一起是因为它们都是字符的序列,数字可以当做一种特殊的字符串
字符串和数字作比较的时候,会把字符串转化为数字的形式,看是否是一个合法的数字比如 123->123;123abc->NaN;\r\n\t123\v\f->0;
五、对象与基本类型
概括一下,对象是各种属性的集合(而属性又可以是对象),所以对象是复杂度是无限制的
而一般我们使用toString来得到关于对象的文字描述(通常是字符串);用valueOf获取对象的原始值;
根据图1,当一个对象与一个非对象比较时,需要将对象转化为原始类型;
var str = new String('hello,world');
console.log(typeof str.toString()); //string
console.log(typeof str.valueOf());//number
六、自身比较
基本类型的比较,如果2个值相同,则为true,而对象比较特殊,只有地址相同才相等。当比较两个引用值时,比较的是两个引用地址,看它们引用的原值是否为同一个副本,而不是比较它们的原值字节是否相等。
数据库索引
众所周知,索引是用来提高sql语句的查询效率的,那么索引到底是什么,我们该在什么时候建立索引,该如何取建立一个好的索引呢?
索引的原理
索引是一种数据结构,来看一下几个最基本的算法,比如我要查找一个id = 8888的用户,
select * from users where id=8888 limit 1;
首先想到的就是顺序查找,直到查到一条id为1 的元素为止,显而易见,这个算法的复杂度是O(n),是很糟糕的,理论上当n越大,开销越大。进而想到有些比较好的算法,二叉树,二分查找,但是都是有要求的,二叉树只能针对二叉树的数据结构起作用,二分查找也只能对有序的数据结构起作用,而数据库本身可以维护着一套符合特定算法的数据结构,可以用某种方式指向数据的数据结构,而我们使用的mysql采用的是B+树的方式建立所索引的。

如图所示,是一棵高度为2的B+树,也可以很清晰的看到其特点
1.所有的记录都存放在叶子节点
2.所有的数据都按顺序排列(到最后通过二分查找获取数据)
3.叶子结点通过双向链起来,便于定位插入新的叶子结点
为什么说它优秀呢?通常数据库索引的消耗来源于磁盘io,而B+树,一个叶子节点对应着一个页,理论上,只需要读取m次(树的高度)磁盘,就可以得到数据所在节点
当产生一个新的元素,存在两种情况
1.插入所在页的叶子结点没满,直接插入
2.当叶子结点已满,会将此叶子结点一分为二,在父节点增加一个新的结点,因此这种方式不会影响兄弟结点
索引的类型
1.普通索引
正常的索引,没有限制
2.唯一索引
与普通索引类似,不同的就是:索引列的值必须唯一,如果是组合索引,则列值的组合必须唯一,创建方法和普通索引类似。
坑:如果一开始没有想好该字段建唯一索引后,由于表中已经存储了大量的数据,这时候就需要考虑去除重复项的事情了,而唯一索引有条语句
alert ignore table wx_fans add unique index(openid)是可以帮你省却很多操作的
3.全文索引
与普通索引不同,适合于大字段处理,举个例子,搜索一段文字,你不需要把全文都输入查询,只需要输入关键字
4.组合索引
较为复杂点,多经常有多个限制条件的sql语句适用,比如搜索来源为4,访问途径是2的用户
select user_id from users where from=4 and mtype=2 limit 100;
这时候可以建立 (from,mtype)的组合索引,比2个索引分开建立更有效率,但需要注意的是mysql有最左前缀的组合,所以只有from,mtype或者from查询的时候才能使用索引,而单mtype是无法享受的
什么情况建立索引?
1.对经常使用where查询的字段设置索引
2.数据库不要出现null值,因为索引是无法检索null值所在的列的
3.短索引(没用过),意思就是去某个字段的前几个字符建立索引
4.对数据量很大,但是重复值很多的不要去建立索引
5.索引的数据类型最好是简单而又小的,比如int型
前言:为什么要使用设计模式?
设计模式并不是生来就有的,也是前人大量编码,最后总结出来的一套代码结构设计经验,根本目的也是为了增加代码的复用性和可维护性。
顺便说一下设计模式很看重一个原则->开闭原则,会在下面的示例中得到体现!简单的来说就是说对扩展开放,对修改关闭。
工厂模式
工厂模式是一种实例化对象的模式,是用工厂方法代替new操作的一种方式
工厂模式根据抽象的程度,可以分为简单工厂模式,工厂方法模式,抽象工厂模式。
Ps:对于一些功能相似的类,我们通常会提供一个抽象接口,把公共方法暴露出来,供调用者实现具体的逻辑。
示例讲解
以保险为例
1.简单工厂模式
由一个工厂类根据传入的参数决定创建哪一种产品的类,其实属于一种比较自然的再封装,我们通常也会在代码设计中不经意的使用
interface Create_product {
public function getProducts();
}
//xyz的产品类
class Product implements Create_product
{
public fucntion getProducts()
{
//todo get products by api
echo 'get products successfully';
}
}
//anlian的产品类
class Product implements Creat_product
{
public fucntion getProducts()
{
//todo get products by api
echo 'get products successfully';
}
}
class Simple_facrtory {
public static function createProduct($supp_name)
{
if ($supp_name=='Xyz') {
return new Xyz\Product;
}
if ($supp_name=='Anlian') {
return new Anlian\Product;
}
}
}
$product = Simple_factory::createProduct('Xyz');
$product->getProducts();
优点:客户端免除了具体产品对象的创建,统一使用工厂去创建对象
缺点:违背了开闭原则,当需要有新的产品的时候,会在工厂类的基础上修改,很容易引发错误。
2.工厂方法模式
对简单工厂模式进行了抽象,有一个简单抽象工厂类负责制定以下规范,一般在这种模式中,工厂类会与某个具体的产品类一一对应。
//抽象产品类的方法
interface Create_product {
public function getProducts();
}
//xyz的产品类
class Product implements Create_product
{
public fucntion getProducts()
{
//todo get products by api
echo 'get products successfully';
}
}
//anlian的产品类
class Product implements Creat_product
{
public fucntion getProducts()
{
//todo get products by api
echo 'get products successfully';
}
}
//将对象的创建抽象成一个接口
interface Create{
public function product();
}
class FactoryXyz implements Create{
public function product()
{
return new Xyz\Product;
}
}
class FactoryAnlian implements Create{
public function product()
{
return new Anlian\Product
}
}
$factory = new FactoryAnlian();
$product = $factory->product();
优点:实现了开闭原则,对于新增的产品,只需要新增对应的产品类和工厂类,不需要对已有代码的修改,降低修改的风险
缺点:对于不同种类的产品,表示无能为力
3.抽象工厂模式
先举个例子,通过上面2个示例,我们制造这个产品了,但是我们有产品后,又需要去搞订单了,是不是又要创建另外的一个工厂类专门来处理订单呢?显然是不合适的,这时候,我们就会想,是不是可以把相关联的产品(产品和订单)放到一个工厂里,也就没必要再新开一个工厂了!
interface Create{
public function product();
public function order();
}
class FactoryXyz implements Create{
public function product()
{
return new Xyz\Product;
}
public function order()
{
return new Xyz\Order;
}
}
class FactoryAnlian implements Create{
public function product()
{
return new Anlian\Product;
}
public function order()
{
return new Anlian\Order;
}
}
$factory = new FactoryXyz();
$product = $factory->product();
优点:抽象工厂模式,核心在于'一系列', 单个工厂可以生产多个相关的产品。便于在业务中切换工厂。
缺点:显而易见,当出现新的产品的时候,改动开销就很大了,需要在每个工厂类中都加入对应的产品。比如说新增了一个用户,那么就需要在这每个工厂里都加一个用户的实现了,也就是无法支持新增产品,但可以支持多个不同的工厂!
总结:这三种模式并不是说哪个一定好,具体的使用要根据对应的环境来决定的!
查询数据
$query = $this->db->query('select * from xxx');
/**
辅助函数
【查询】
$query->num_rows(); //查询结果集的行数
$query->num_fields(); //返回当前请求的字段数目(即列数)
$query->free_result(); //释放结果集
【其它】
$this->db->insert_id();//执行数据插入时的ID
$this->db->affected_rows();//影响的行数
$this->db->count_all('table_name');//返回某个表的总行书
$this->db->platform();//数据库平台(mysql,MS SQL...)
$this->db->version();//数据库版本
$this->db->last_query();//最近一次查询
$this->db->insert_string('table_name' , $data); //生成标准的insert语句
$this->db->update_string('table_name' , $data); //生成标准的update语句
原文更正:
where条件里写大于、小于、不等等符号的时候,要留空格。
误:$this->db->where('start_time!=','2013');
正:$this->db->where('start_time !=','2013');
CI框架从3.0开始,输入类Input开始支持用数组的方式去取变量值。例如:
以前(2.x):
$user_id = $this->input->post('user_id', true);
$nickname = $this->input->post('nickname', true);
$version = $this->input->post('version', true);
...
$address = $this->input->post('address', true);
改进(3.x):
$keys = array('user_id', 'nickname', 'version');
list($user_id, $nickname, $version, $address) = $this->input->post($keys, true);
使用 input_stream() 来获取php://input流数据,例如 PUT 请求
以前:
$rsv = file_get_contents("php://input");
$data = json_decode($rsv,1);
$user_id = intval($data['user_id']);
$nickname = stripSql($data['nickname']);
$version = stripSql($data['version']);
改进:
$keys = array('user_id', 'nickname', 'version');
list($user_id, $nickname, $version, $address) = $this->input->input_stream($keys, true);
在http和https的兼容上面,$this->config->base_url() 添加了第二个参数 $protocol,可以传入http/https。如果传入【""】,会得到//开头的链接,表示自适应。
示例:
$CI =& get_instance();
$url = $CI->config->base_url("yilucaifu/buy/1024", "");
/**
* window.location="//shop.ci123.com/flashsale/yilucaifu/buy/1024";
*/
get(), post(), get_post(), cookie(), server(), user_agent()在没有取到数据的时候,返回NULL而非FALSE。
意义:
在以前(2.x),$p = $this->input->get('p', true); isset($p) 始终为真;到3.x后,如果没有p参数,isset($p)为假。
BASEPATH, APPPATH 被定义为了绝对路径,在脚本里可以直接使用这些变量了。
CI 3.x原生支持composer。新建composer.json,填写内容后update就可以使用了。
示例一:
var x = [1,2];
x.k = 'v';
console.log(x);
console.log(x.length);
结果是:
[1, 2, k: "v"]
2
示例二:
var x = [1, 2];
x.get = function(){
alert('function get');
}
console.log(x);
console.log(x.length);
结果是:
[1,2] --注释1
2
注释1:展开后是:
0:1
1:2
get:function()
示例三:
var x = new Object();
x[0] = 1;
x[1] = 2;
x.get = function(){
alert('function get');
}
console.log(x);
console.log(x.length);
结果是:
Object {0: 1, 1: 2} --注释2
undefined
注释2:展开后是:
0:1
1:2
get:function()
示例四:
var m = [];
var n = new Object();
console.log(m instanceof Array, m instanceof Object);
console.log(n instanceof Array, n instanceof Object);
结果是:
true true
false true
【结论1】:从上面可以看出来,JS中的数组仅仅是一种特殊的对象,对象和数组都可以具有属性和方法。数组具有 length 属性,而对象没有。当数组具有属性或方法时,属性和方法不会让数组的 length 增加。
示例五:
var p = [];
console.log(p.length);
p[100] = 1; --注释3
console.log(p.length);
结果是:
0
101
注释3:或者p['100']
示例六:
var p = [1,2,3,4,5]
console.log(p, p.length);
p.length = 3;
console.log(p, p.length);
p.length = 5;
console.log(p, p.length);
结果是:
[1, 2, 3, 4, 5] 5
[1, 2, 3] 3
[1, 2, 3] 5
【结论2】:当值被分配给大于数组本身长度的索引时,length 会自动增加到新的长度;当 length 变小时,索引超过数组长度的元素将被删除。(恢复length也无法恢复数组元素)
一:下面看一个腾讯面试题,主要知识是Js的线程问题。(有删减)
var cnt = 0;
for(var i = 0; i < 10; ++i) {
setTimeout(function() {
cnt += i;
}, 0);
}
setTimeout(function(){
console.log(cnt);
}, 0);
由于Js是单线程,遇到循环的时候setTimeout会在循环结束后才执行,所以cnt所加的i总是10,最后cnt的值是100。
var cnt = 0;
for(var i = 0; i < 10; ++i) {
setTimeout(function() {
cnt += i;
}, 0);
}
console.log(cnt);
稍作改动,代码的运行结果是0,很容易理解。
二:向 setTimeout 传递字符串字面量
var s = 1;
function test()
{
var s = 2;
setTimeout('console.log(s)', 0);
}
function test2()
{
var s = 2;
setTimeout(function(){
console.log(s);
}, 0);
}
test();
test2();
传入字符串字面量时,字面量会在全局作用域内被解析,所以上面输出 1 和 2 ;