编 写:袁 亮
时 间:2014-05-20
说 明:关于ip的那些事
一、ip传递过程
1、【真实客户端】 ==> [多级代理服务器] ==> [CDN加速] ==> [前端代理nginx|squid] ==> 【apache】==> 【PHP】
2、中文括号的是必然会经过的,英文括号是可能经过的
3、标准的ip传递是REMOTE_ADDR和HTTP_X_FORWARDED_FOR,前一个跟当前服务连接的真实ip,后一个是请求到前一个ip之前,经过了哪些代理
4、REMOTE_ADDR是不可伪造的,HTTP_X_FORWARDED_FOR是可以任意修改的
5、按标准,每传递到下一层,都会将上一层的实际ip地址加入到HTTP_X_FORWARDED_FOR中,继续传递
6、对每一层来说,只有上一层的时间地址是可信的(REMOTE_ADDR),HTTP_X_FORWARDED_FOR均有风险
7、真实情况中,到了cdn或者前端代理之后,ip传递都是可信的(我们自己可控制),之前的都有篡改的危险
二、各服务的真实ip传递情况
1、CDN 快网的cdn会将用户的实际地址或者代理服务器地址传递到后面的服务中
$_SERVER["HTTP_USER_IP"] 【不用快网的时候可伪造】
$_SERVER["HTTP_FW_ADDR"] 【不用快网的时候可伪造】
测试了一个新的cdn测试,没有传递真实ip过来
2、nginx代理的情况下,可以使用x_real_ip来获取真实ip(有cdn的时候,该值获取的是cdn的ip地址)
$_SERVER["HTTP_X_REAL_IP"] 【不用nginx的时候可伪造】
3、$_SERVER["HTTP_CLIENT_IP"] :代理服务器发送的客户端真实ip【可伪造】
三、现在使用的获取ip函数
a、如果有HTTP_CLIENT_IP,则该ip为用户ip(可被伪造)
b、如果有HTTP_X_FORWARDED_FOR,则将HTTP_CLIENT_IP也加入到HTTP_X_FORWARDED_FOR,判断HTTP_X_FORWARDED_FOR中的ip是否是内网的,取第一个非内网的ip为客户端真实ip
c、经过以上两步还没有取到ip的话,则根据REMOTE_ADDR取用户的ip
ps:该函数的问题在于,前面两个的ip都是可以被任意伪造改写,从而导致获取不到用户的真实ip情况
四、附:(线上使用的获取ip函数)
function getIp(){//获取IP函数
$ip = false;
if(!empty($_SERVER["HTTP_CLIENT_IP"])){
$ip = $_SERVER["HTTP_CLIENT_IP"];
}
if (!empty($_SERVER['HTTP_X_FORWARDED_FOR'])) {
$ips = explode (", ", $_SERVER['HTTP_X_FORWARDED_FOR']);
if ($ip) {
array_unshift($ips, $ip);
$ip = FALSE;
}
for ($i = 0; $i < count($ips); $i++) {
if (!preg_match("/^(10|172\.16|192\.168)\./", $ips[$i])) { // 判断是否内网的IP
$ip = $ips[$i];
break;
}
}
}
return ($ip ? $ip : $_SERVER['REMOTE_ADDR']);
}
分类: web后端技能树
http 1.1 和 http1.0 主要区别
编 写:袁 亮 时 间:2016-01-12 说 明:http 1.1 和 http1.0 主要区别 一、持久链接keep-alive 1、标准的1.0版本中,每次请求都必须重新建立连接、传输数据、关闭连接 但有些http服务和浏览器也实现了Connection: Keep-Alive的功能 2、在1.1版本,默认就是Connection: Keep-Alive 可以在同一次TCP连接中,多次传输数据 减少了重新建立连接的开销,特别是当一个网页中有很多图片、js、css等的时候会非常有用 但这也有可能会导致TCP一直不释放,从而影响性能,需要权衡设置 二、增加了HOST 1、在1.0版本中,不支持HOST,同一ip同一端口,只能供一个服务使用 2、1.1版本中,支持HOST来创建虚拟主机 三、带宽优化 1、1.1版本中,增加了RANGE头来实现断点续传,从而防止下载中断之后又要全部重新上传 2、增加压缩,通过Accept-Encoding头来实现,减少数据传输 四、其他 1、缓存策略 2、新增http状态码 3、身份认证、状态管理 4、我们服务器上有些apache还是返回http 1.0,感觉不大正常 附:参考文档 1、http://blog.csdn.net/elifefly/article/details/3964766 2、http://www.cnblogs.com/qqzy168/p/3141849.html 3、http://www.cnblogs.com/huangfox/archive/2012/03/31/2426341.html 4、http://www.360doc.com/content/14/0730/09/1073512_398058058.shtml
xhprof实际使用过程中的一些注意事项
编 写:袁 亮
时 间:2016-01-12
说 明:xhprof实际使用过程中的一些注意事项
一、扩展安装
1、前置说明
1.1 这个组件作为性能分析工具,测试环境有时候不能重现问题
1.2 直接在生产环境安装,容易导致当前服务受影响或者不可用
1.3 开启对性能也有一定影响,特别是大流量的情况下,直接全部开始,那就悲剧了
2、分流开启(成本适中、危险性低)
2.1 采用nginx分流,使一小部分流量请求发送到安装了xhprof的服务上
2.2 安装的那台服务器,可用开启监控,并跟生产环境对比
2.3 既可以达到采集到实际数据,也不影响大部分的用户和业务
3、流量复制(成本较高,基本无危险)
3.1 将正式环境的流量复制到测试机上,开启监控查看
3.2 优点是对原业务几乎无影响,也方便进行流量放大,做压力测试等
3.3 缺点是之前没做过,略有点麻烦
二、程序开启并记录
ps:下载http://pecl.php.net/get/xhprof-0.9.2.tgz,参考其中的example/example.php的写法
1、开启监控
xhprof_enable();
ps:只在需要的地方开,不要全部开,或者以一定概率开启
2、停止监控采集
$xhprof_data = xhprof_disable();
3、采集监控数据
$XHPROF_ROOT = realpath(dirname(__FILE__) .'/..');
include_once $XHPROF_ROOT . "/xhprof_lib/utils/xhprof_lib.php";
include_once $XHPROF_ROOT . "/xhprof_lib/utils/xhprof_runs.php";
$xhprof_runs = new XHProfRuns_Default('可以保存到自己定义的文件夹中,未设置则采用php中的默认设置');
4、保存监控数据
$run_id = $xhprof_runs->save_run($xhprof_data, "保存数据的后缀,作为同一项目的区分用");
ps:可以将数据保存在一个挂载盘中,这样可以在一台统一的服务器上统一查看调用
ps:后期也可以考虑自动化,针对慢的请求,直接在php配置中auto_prepend_file增加一段监控程序,按一定比例采样,并汇总分析
三、显示性能分析
1、可以在任意一台能访问存储的监控数据的地方
2、复制下载文件中的xhprof_html文件夹,并放在可web访问的地方
3、通过保存时候生成的run_id和自己设置的后缀,即可访问
4、重点关注callgraph.php,生成的调用链接,主要耗时的调用链有非常明显的颜色标注出来,一眼就能看到性能瓶颈在哪
ps:这个需要graphviz和graphviz-gd
svn管理流程实践
整 理:吴万利
时 间:2015-01-08
说 明:svn管理流程实践
svn目录结构
trunk 主干:存储最新稳定的版本
tags 标记:主要保存比较完整的版本标记,类似里程碑
branches 分支:用于分工操作,以开发分支、用户名、日期为目录存储
svn工作模式
基础结构准备
选定trunk为主要开发文件夹
tag为发布版本的地方(可能也有紧急的bug修复,之后要将代码合并回主干)
branch为分支目录(bug修复、模块独立开发等)
现有的文件结构
trunk/ 主要开发的目录
*.php
tag/ 版本发布目录(发布tag一定要标记信息!)
release_1.0 已经发布的一个版本(1版本号,0修订号)
branch/ bug修复,独立模块开发等
问题应对流程
- 日常的开发怎么办?
答:日常可以在trunk里面进行开发,周期不长开发测试完成可以打包出来进行测试。- 开发完成之后由管理人员操作打包得到
http://svnxxx.xxx.com/svn/vshop2_trade_module/tag/release_2.0 - 在测试机上测试稳定之后就可以准备上线
上线:可以在对应项目目录下面执行svn switch命令(我的方案)
- 开发完成之后由管理人员操作打包得到
- 线上的项目出现问题怎么办?
- 紧急而且简单
- 直接在release里面修改(其实不推荐,而且测试机的配置,同样用switch命令?),然后测试提交,在线上更新。
- 通知trunk、branch里面的dev进行merge(merge前提交所有改动!)
- 不紧急而且较复杂
- 在branch里面copy一个release_1.0版本为dev_1.0_bugfix进行修改
- 测试通过之后发布为tags/patch_1.1 通知trunk等进行合并操作
- 紧急而且简单
- 开发新的独立模块怎么办?
答:可以考虑在branch下复制一个当前稳定版本的dev_2.0_yilucaifu出来进行修改,测试完成之后可以独立上线,但是不要忘记合并。
情景模拟
0. 情景准备
svn仓库结构:
branches
tagsrelease_1.0
trunk
服务器上代码结构:
正式版
tvshop2_online(svn:tags/release_1.0)
测试机
tvshop2_online_dev(svn:trunk)
1. 上线的东西出问题,需要调试
- 对于tag版本出一个bugfix分支
svn cp
http://svnxxx.xxxx.com/svn/tvshop2/tags/release_1.0http://svnxxx.xxxx.com/svn/tvshop2/branches/dev_1.0_bugfix
-m '1.0bug修复' - 测试版切换到分支
tvshop2_online_dev:
svn switch http://svnxxx.xxxx.com/svn/tvshop2/branches/dev_1.0_bugfix - 测试版debug,测试提交
tvshop2_online_dev:
svn ci -m 'debug message' - 发布一个新的版本
svn cp
http://svnxxx.xxxx.com/svn/tvshop2/branches/dev_1.0_bugfixhttp://svnxxx.xxxx.com/svn/tvshop2/tags/patch_1.1
-m 'bug修复' - 改动上线
tvshop2_online:
svn switch http://svnxxx.xxxx.com/svn/tvshop2/tags/patch_1.1 - 清理无用分支dev_1.0_bugfix
svn del http://svnxxx.xxxx.com/svn/tvshop2/branches/dev_1.0_bugfix -m '已经上线'
- 合并改动到主分支
tip:一般线上的紧急调试都不会太大,所以合并一般问题都不会很多- 切换测试机为主分支
tvshop2_online_dev:
svn switch http://svnxxx.xxxx.com/svn/tvshop2/trunk - 合并改动到主分支(推荐在windows下用工具辅助做)
svn merge http://svnxxx.xxxx.com/svn/tvshop2/tags/patch_1.1/ ./ - 下次提交将改动一起提交即可
- 切换测试机为主分支
2. 新的模块的开发
- 开发之前先大致确定一下可能的改动,是否跟原来的开发改动了同一块地方。
- 对于需要共同修改的地方在合并的时候必须小心处理,可以跟原来的开发一起查看改动是否合理。
3. 优点:
- 线上代码稳定,可靠性高(除非有人故意删除release)
- 回退方便,能够很清楚的知道上个版本是哪个
4. 缺点:
- 操作复杂,繁琐,比较容易搞混当前的版本是哪个
- merge回当前开发分支的时候可能会引起冲突(无法避免)
- 线上如果有人修改可能会引起树冲突,所以切换之前需要提交所有改动
5. 原则总结:
- 在执行switch的之前一定要提交所有的改动。
- 每次发布新版本之后其他分支需要从trunk上merge来获取最新的版本(冲突的话需要协商解决)。
仓库迁移记录
- 准备好即将使用的svn仓库
- 在线上先co出两个文件夹备用(svnshop2+svnshop2_dev)
- 将线上的代码export一份作为一个基础版本,并发布一个tag(release_1.0)
- 将本地开发的所有改动提交到之前的仓库
- 将之前的仓库文件导入到现在的svn里面的trunk中
- 在线上测试机co trunk,测试各项功能是否ok(测试一起购、一路财富改动都没有问题)
- 以后上线:trunk发布新的tag,线上执行switch操作(确保线上svn里面的文件没有M状态!)
可能的问题
- crontab怎么办?(直接在服务器上做的alias,没有影响原结构)
- 静态文件上线?(只能针对静态文件单独做合并、上线)
- 以后数据库的改动怎么同步?
VIM PHP IDE的安装步骤
前言
文件包所在
\\192.168.0.18\运维网络硬盘\y袁亮\vim-php-ide
php-vim-fool.tgz是fool式安装php-vim-full.tgz是full式安装
其实就是相差一个YCM插件,YCM插件需要clang编译,所以比较烦。
FOOL安装
最好要求php5.3.9以上版本,也最好安装php-xml
yum install php-xml
关于自动补全
- 最好,也至少安装一下ctags不然很多东西用不起了。
yum install ctags。- 如果没有权限安装,那也只能作罢。
fool版的代价是不太友好的自动补全,当然也没有路径补全了=_=
安装步骤:
- 使用
winscp将php-vim-fool.tgz上传到工作用户目录下。 - 执行指令
tar xzvf php-vim-fool.tgz -C ~/ - 然后就ok了
关于配置文件
- 位置在
~/.vimrc - 打开
vim ~/.vimrc,先使用zM折叠所有方便查找,za单独打开和关闭折叠。
full安装(其实就是自动补全的差距)
需要安装的外部依赖:
- git是必须的
yum install git - gcc gcc-c++
yum install gcc gcc-c++ - clang
- 先添加epel源,
yum install epel-release yum install clang
- 先添加epel源,
- python-devel
yum install python-devel - cmake
yum install cmake - ctags
yum install ctags - 可能需要php5.3.9以上的版本,不然需要关闭phpmd检查
安装vim-php
- 使用
winscp将php-vim-full.tgz上传到工作用户的目录下,即~/下面,github太慢,还是直接压缩包来得好。 tar xzvf php-vim-full.tgz -C ~/vim ~/.vimrc查看有没有报错(一般没有),然后:PluginUpdate,时间可能有点久,这不是必要的,可以直接下一步。- 进入
~/.vim/bundle/YouCompleteMe/, 执行./install.py编译一下,可能比较久。- 提示缺少
argparse安装pip install argparse - 如果没有
pip,安装yum install python-pip
- 提示缺少
- 如果编译失败,请查看依赖有没有安装成功
- 安装成功后可以在vim下键入
:PluginUpdate vim-shippets更新模块。
VIM PHP IDE的基本操作
前言
安装步骤的链接
关于安装步骤:
- 分full和fool两个版本,版本差距在自动补全的插件。
- 最好安装ctags,如果不安装ctags自动补全将不完善,tagbar也无法工作。
- 可以考虑一下vim的练级攻略。
语法检查
文件在保存时会检查语法错误和规范
一共有三种警告:
p>php的语法错误, 可以使用:Php主动检查s>不符合prs2规范, 可以使用:Phpcs主动检查m>质量检验, 可以使用:Phpmd主动检查
格式修复
nnoremap <silent><F7> :call PhpCsFixerFixDirectory()<CR>
nnoremap <silent><F8> :call PhpCsFixerFixFile()<CR>
F8可以修复一些不符合psr2的规范,但是存在一些问题,如果只是定义了函数名或是类名的一些没有实际作用的代码可能会被删除,安全性有待评估。
自动补全
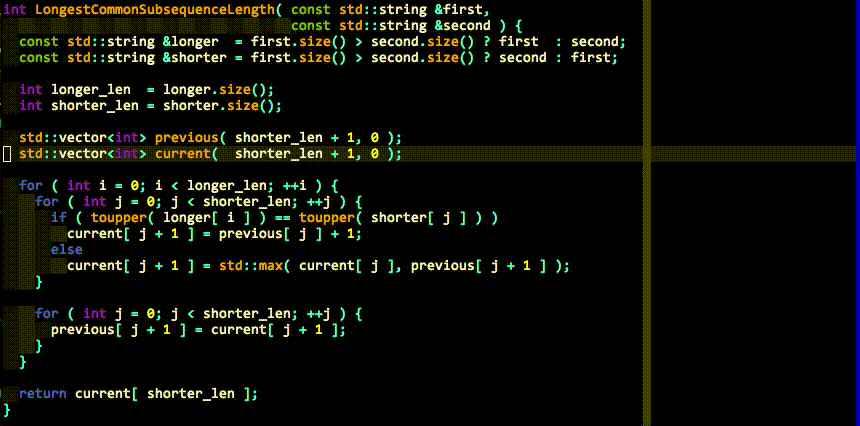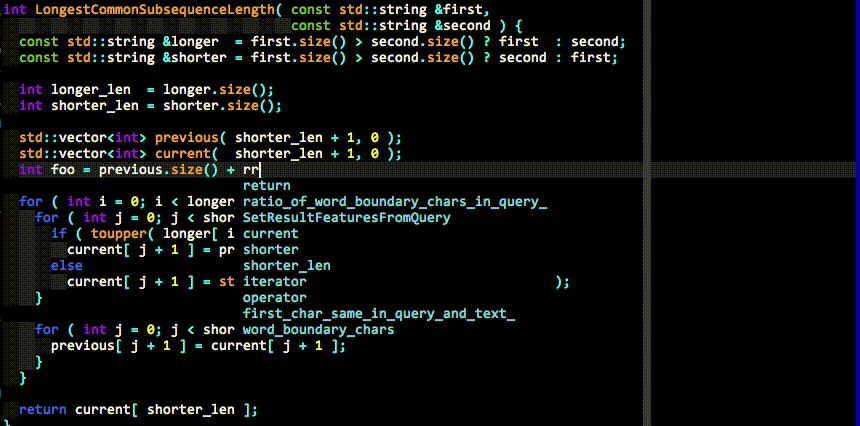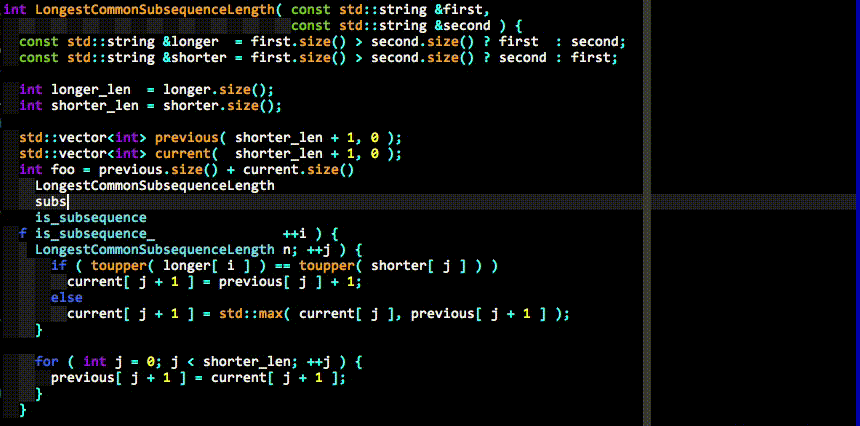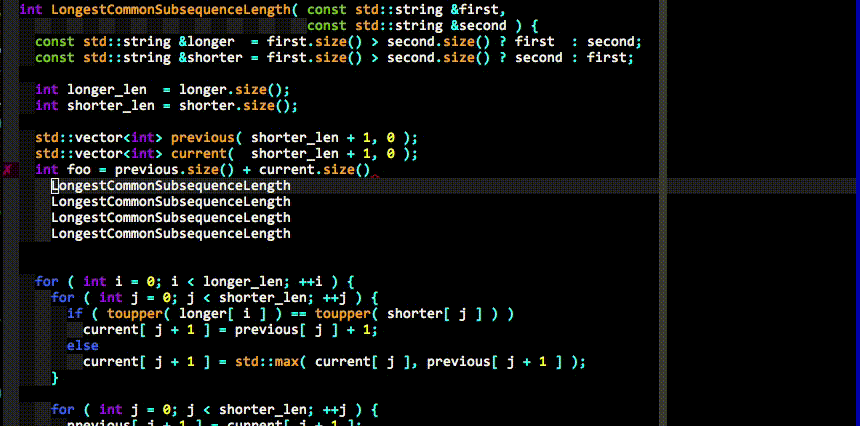
full基本操作:
- 两个字符后开始自动补全
- tab键选择,shift-tab逆向选择
- 可以使用ctrl-n向下,或是ctrl-p向上选择
如果是fool版:
- 不能自动开启补全,不能像图中那样方便。
- 必须使用
<ctrl-x><ctrl-o>开启补全 ctrl-n和ctrl-p无法选择, tab可以使用- 其他相同
一般只支持系统函数补全,如果要支持自己编写的函数补全,需要如此:
- 在项目顶层目录下执行指令
ctags -R - 必需在项目顶层目录,即
ctags文件所在的目录打开vim - 打开文件,不要退出vim,使用
NERDTree和ctrl-p查找和打开文件,如果需要创建文件,可以使用ctrl-p打开文件。 - 如果创建了新的类,将必须在项目顶层目录执行
ctags -R的指令,当然可以在vim执行:!ctags -R,在不退出vim的情况下更新ctags文件
可以通过tags来实现require的补全
对于composer的补全,默认composer是全局安装的,好像失败了。
代码块
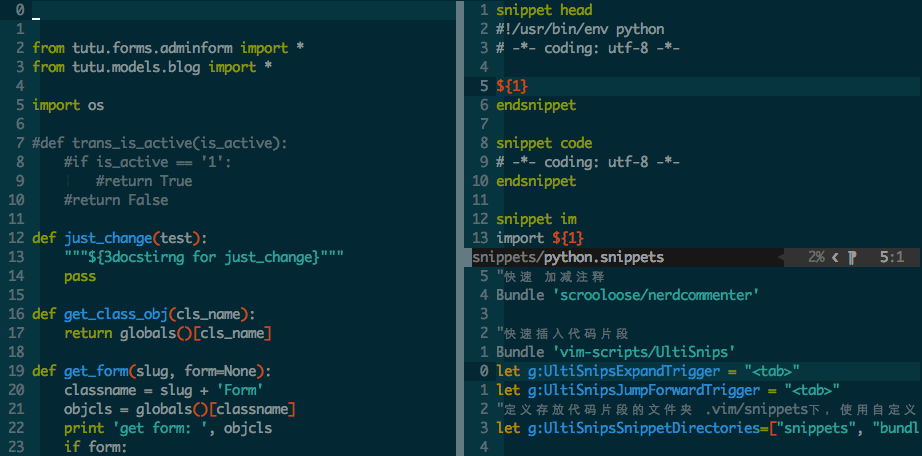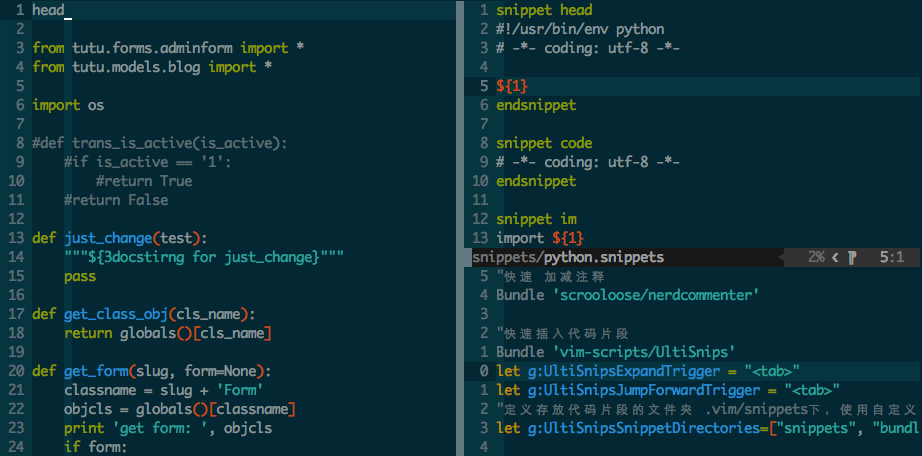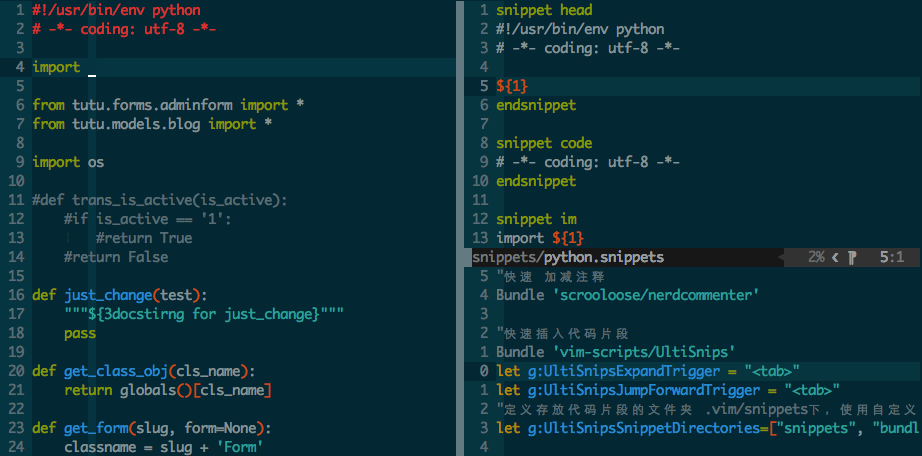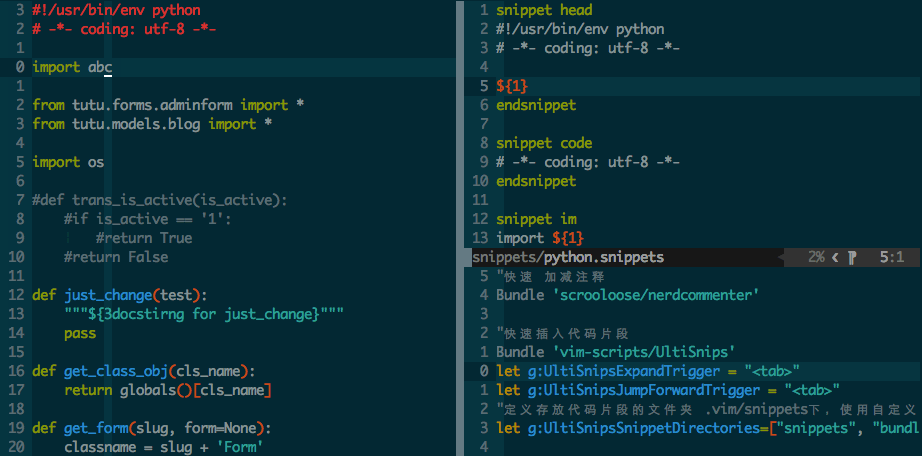
已经将php的模板文件软连接到用户主目录下,可以自行查看修改
vim ~/php.shippets
?-tab 可以生成这样的代码 <?php ?>
f-tab可以生成这样的代码
function ()
{
}
pub-tab可以生成
/*
* undocumented function
* @return void
* /
public function name($param)
{
return null;
}
c-tab
class filename
{
}
class-tab可以生成一个带注释的class
文件目录和代码浏览
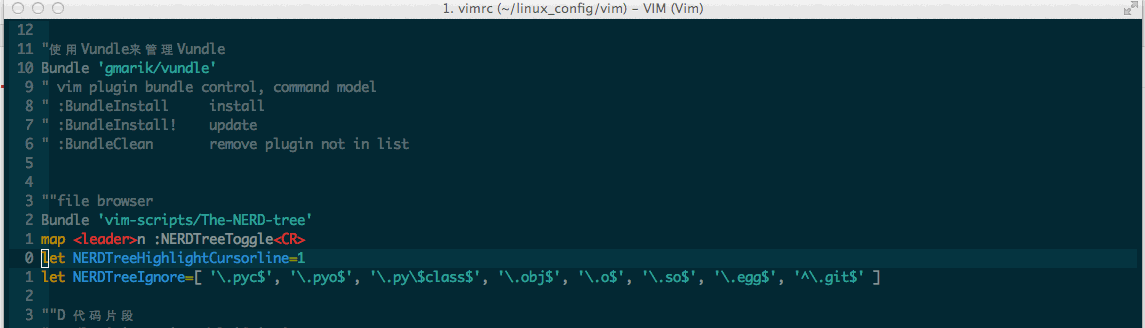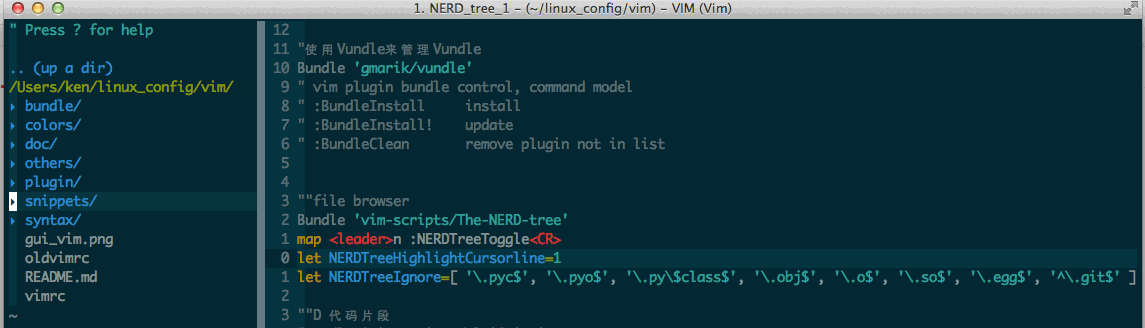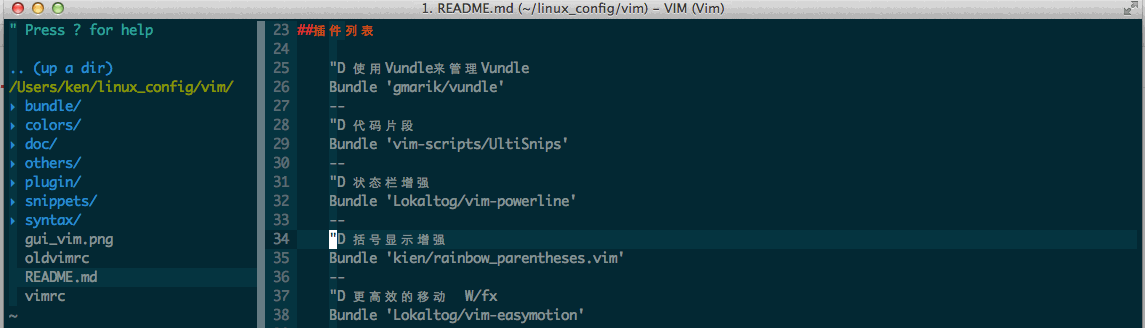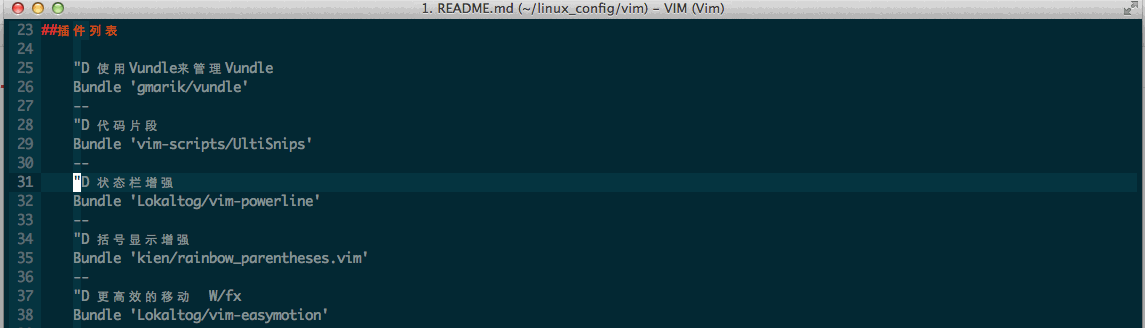
F2 打开文件目录
在NERDTree中按?呼出帮助文档
需要安装ctags
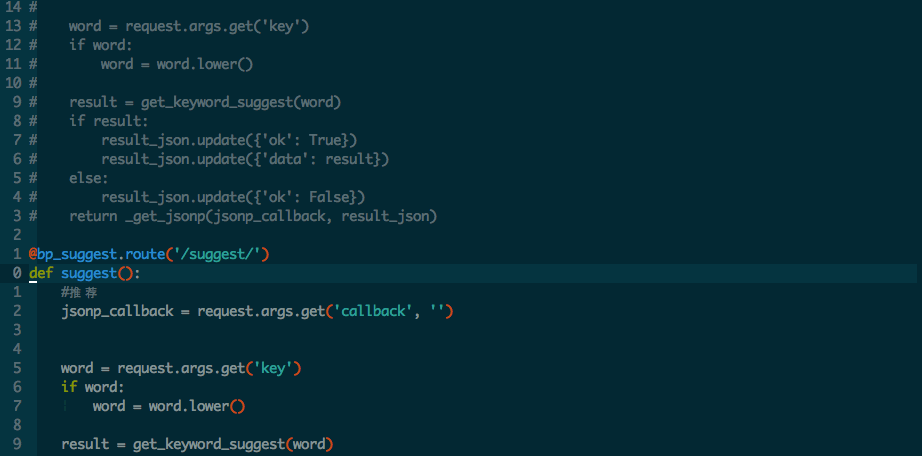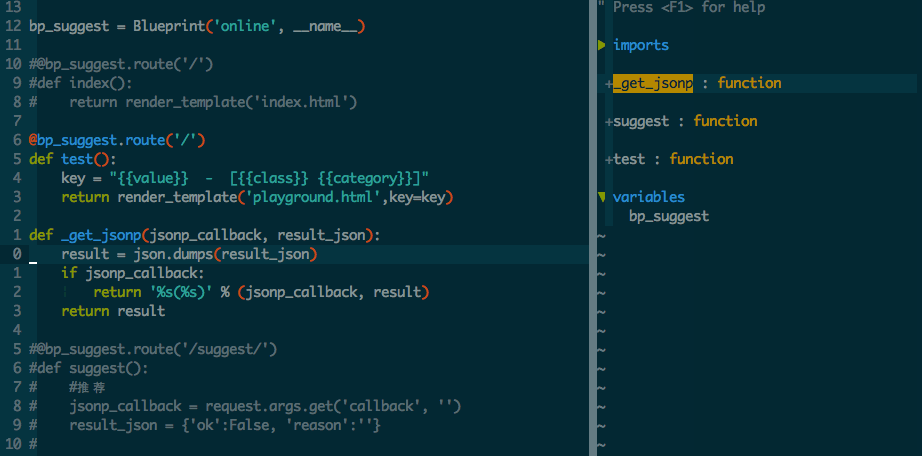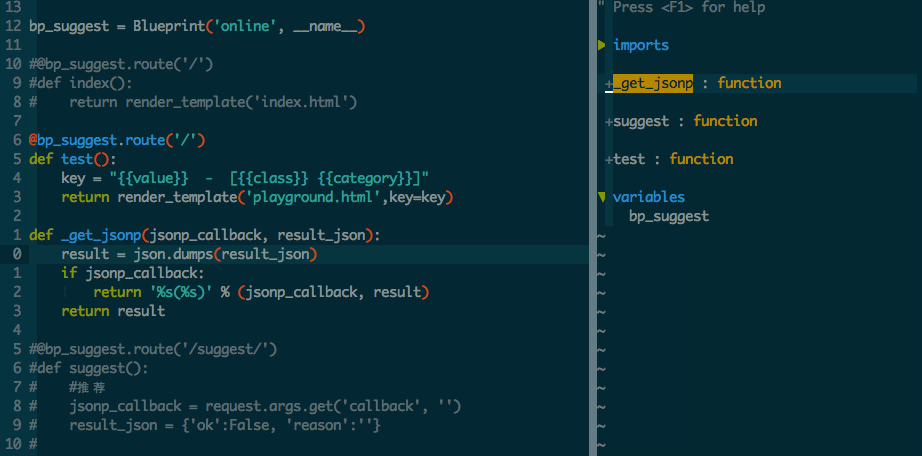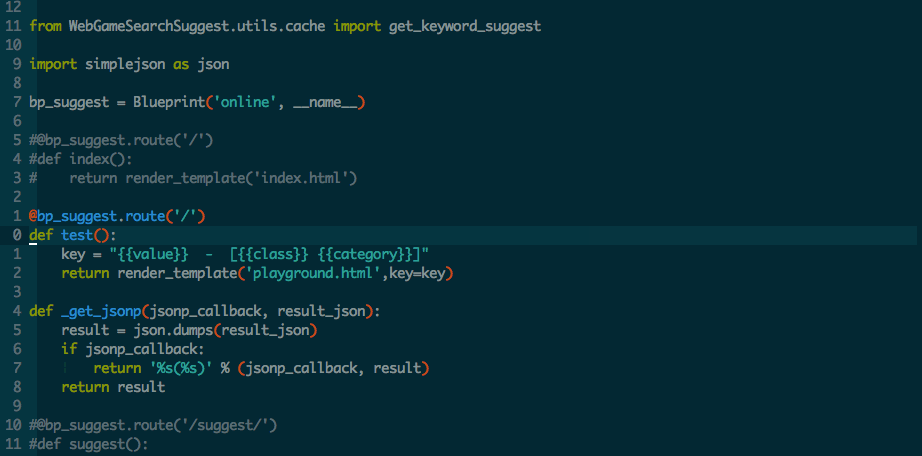
F3 打开代码浏览
模糊搜索
ctrl-p
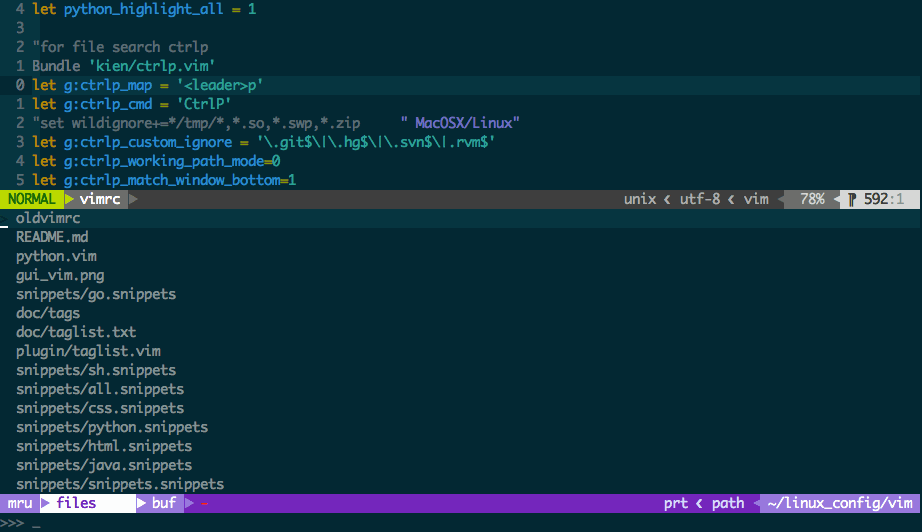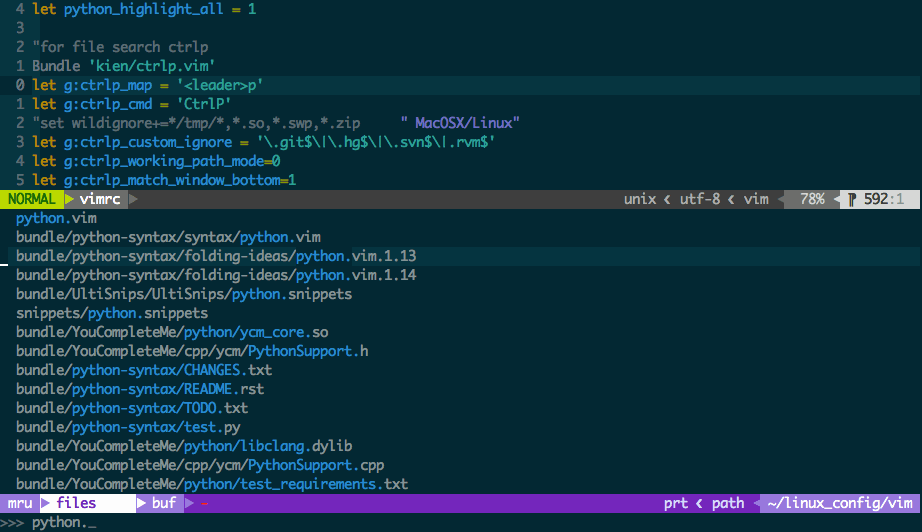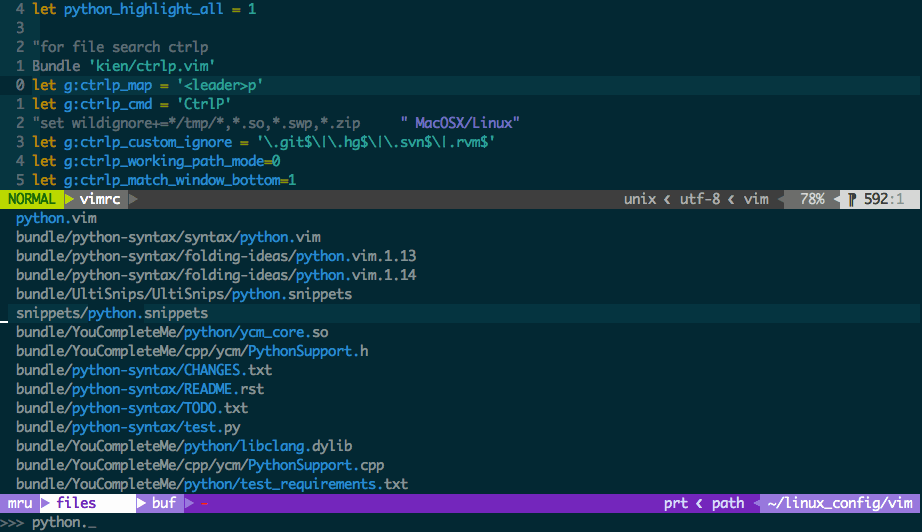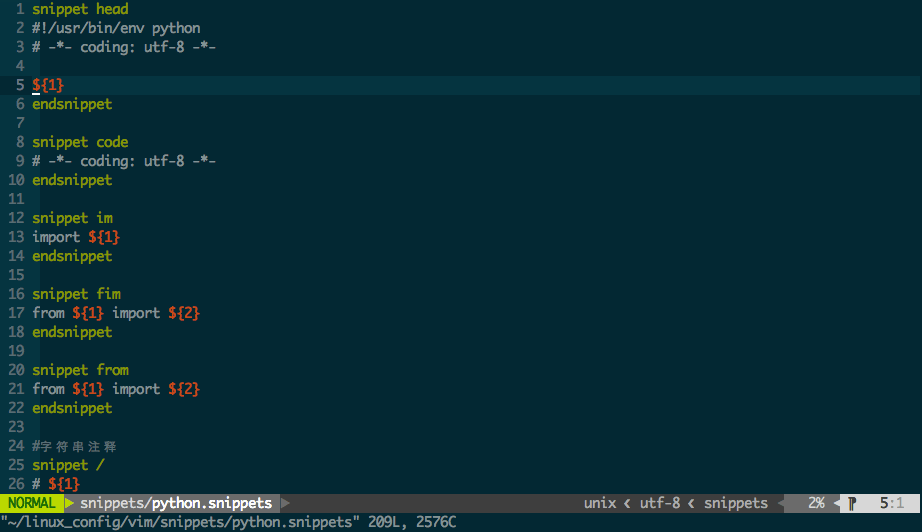
基本不需要设置
ctrl-p 打开模糊搜索
ctrl-k 和 ctrl-j 可以在搜索结果中上下选择
ctrl-t 在新标签页打开
ctrl-v 分割打开
ctrl-y 新建文件, 需要先敲入路径和文件名
html tag跳转
在一个html tag上使用%可以跳转与之匹配的tag
官方文档
将光标移动到需要查看的函数上,使用shift-k,就可以查看官方文档a。
符号补全
在使用', ", (, [, {时,会自动补全另一半,同时如果再按各个匹配的另一半,则会跳出。
全局搜索
可以使用命令
:CtrlSF param
也可以设置
nmap <leader><leader>f <Plug>CtrlSFPrompt
<leader>默认是\,所以快捷就是 \\f
因为是全局搜索,所以不要在太顶层目录使用,具体请查看CtrlSF
多光标
ctrl-n 开启选择/选择下一个
下面操作需要在ctrl-n执行后
ctrl-p 取消一个选择
ctrl-x 跳过一个选择
详细vim-multiple-cursor
PS: 可以通过结合全局搜索实现重构
注释
\cc 注释当前行
\cu 反注释当前行
可以通过shift-v实现多行操作
撤销树
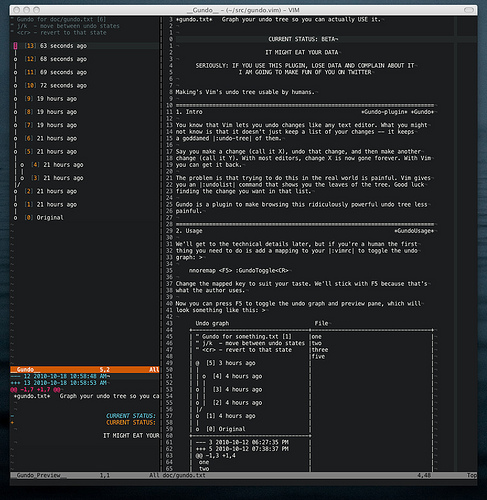
F4呼出撤销树,查看之前的撤销修改
其它一些插件
更好的代码高亮
在php 和 html代码混杂在一起时提供更好的缩进
状态栏美化
显示多余的空格
服务化一般流程
编 写:袁亮
时 间:2015-12-16
说 明:服务化的一般流程
一、理清功能点
1、找到业务对接人
2、找同类功能,其他家比较好的是怎么做的
3、确定功能,可能做什么,哪些不做,后期可能扩展
二、如果在已有的基础上升级
1、理清原来代码
2、什么地方,做了什么事
3、有哪些代码是冗余的
4、记录文档
三、数据字典设计
1、根据功能设计数据字典初稿
2、对照功能点,一个个的过,看是否能实现预期的功能
3、如果后期要升级,是否好扩展
4、业务方面能支持的情况下,看是否会有性能瓶颈
5、是否需要增加冗余字典,查询优化
四、接口列表划分
1、根据需求,罗列接口列表
2、重新审查接口列表,是否有重复的
3、不同接口之间是否有部分做的同样的事,是否需要抽离
4、重新根据功能进行接口聚合,分类,整理完整列表
5、拿着接口列表,分别看看需求和现有功能是否能满足
6、给出完整确认的接口列表
五、定义接口
1、根据接口列表写注释
2、需要输入哪些参数,分别代表什么意思
3、这些参数需要做哪些格式验证
4、业务方面需要做哪些验证
5、非查询条件,需要做哪些数据更新操作
6、接口返回什么
六、根据接口定义写代码
1、根据接口定义,编写代码
2、写相应的demo,测试各种情况
3、监控查看接口返回是否正常
4、后期做成能自动监控
七、接口文档
1、编写apidoc需要的注释
2、生成apidoc文档
3、更新到文档库
4、查看文档是否有错误
八、旧项目升级
1、如果是从旧项目升级,需要将旧数据,写脚本导入写服务中
2、旧的代码中,所有涉及到这块的,根据之前列的文档,一个个的改成接口调用
3、改动一处,即进行完整测试,并做相应标记
4、全部改完之后,整体测试
九、上线
1、代码上线前,将旧数据转换脚本启动,并跑完
2、代码通过版本控制器上线,同时转换脚本开启,避免上线过程中产生的新数据未同步
3、上线测试是否正常,并重点关注error_log
4、查看旧数据库是否还有数据新增,以及新数据库数据增长是否正常
5、查看接口监控日志,是否有异常调用
6、关注用户反馈,自己多测几次正常流程,特别是涉及到改动的地方
php文件包含路径问题
编 写:袁 亮 时 间:2015-12-01 说 明:php文件包含路径问题 一、解决什么问题 1、在某些项目代码中,会出现包含出错问题 2、多次include的时候,会发现不知道包含的到底是哪个文件 3、某些项目代码中,找不到对应include进来的文件 二、前置知识:3种路径 1、绝对路径 linux下,以/开头的路径 window下以盘符开头的,比如c:/ 2、相对路径 以.或者..开头的路径 3、不确定路径 非上述两种情况的都是 三、包含路径include_path 1、这是一个目录列表 2、在php查找文件的时候起作用,主要是以下这些函数 include,require,fopen,file,readfile,file_get_contents 3、查找文件的时候,会根据include_path中的目录列表一个个去找,找到之后中止返回 4、功能类似系统中的环境变量 5、可以通过php.ini或者php代码中进行设置(也可以通过php函数读取) 6、默认值是. 代表当前工作目录(简单来说就是访问的第一个php文件所在的目录) 四、查找要包含哪个文件 1、包含的是绝对路径的文件 与include_path无关,直接引用绝对路径所对应的文件 2、包含的是相对路径的文件 跳过include_path,根据工作路径拼接上相对路径,查找文件,如果有则包含,没有则报错 ps:工作路径即访问的第一个php文件所在的目录 3、包含的是不确定路径的文件 3.1 逐个使用include_path中的目录跟不确定路径拼接查找文件,找到则退出 3.2 如果没有找到,则根据包含语句include所在的文件的目录,拼接上不确定路径查找文件 3.3 如果还是没有,则报错 五、解决方案 1、项目的一个公共文件,通过__FILE__,或者__DIR__(php 5.3后),结合dirname来计算获取项目根目录 2、所有文件包含,均通过项目根目录进行拼接,得到绝对路径,再包含 3、使用不确定路径包含文件 3.1 使用不确定路径,包含当前目录或当前目录的子目录下的文件 3.2 这种方法性能较差,因为必然是经过多次查找才能得到 3.3 而且在项目工作目录出现同名文件,则会出现包含到错误文件的情况 3.4 常见于sdk包,一般情况下少用 参考文档: 1、PHP中require和include路径问题详解 http://www.cnblogs.com/rainman/p/4177302.html 2、PHP手册 http://php.net/manual/zh/ini.core.php#ini.include-path http://php.net/manual/zh/function.set-include-path.php
使用token来解决用户信息同步问题
编 写:袁 亮 时 间:2015-11-27 说 明:多应用系统用户信息统一安全升级策略 一、问题 1、post请求之后,后退按钮导致加载失败,提示需要重新提交数据问题的解决 2、用户信息被抓包,会导致账号泄漏问题 二、原因 1、根据http协议,post请求非幂等,不能缓存,因此有响应头Pragma:no-cache 2、后退的时候,浏览器会强制提醒用户,确认是否重新输入数据 3、因此后退会出现白页 三、可能解决思路 1、post请求换成get请求,绕过限制 1.1 私密数据不安全,如果链接发给其他人,会导致账号被盗 1.2 统计代码中,会把这些链接都给存储下来,太危险 2、对get的数据进行可逆加密并加过期时间 还是解决不了上面的两个问题 3、先post发送私密数据过去,然后get跳转 四、完整思路 1、私密数据,必须要走post,不能get 2、先通过服务器间请求,将私密数据post过去 2.1 在客户端对数据进行签名及有效期 2.2 通过post将数据通过服务器与服务器传输 2.3 服务端返回该数据存储的token(类似session存储) 为防止服务器返回较慢,导致token丢失,token以客户端传过去的签名为准 2.4 该数据,只存储一个小时,超过则失效 3、get形式带上token去请求数据 3.1 根据token,取到对应的数据 3.2 用户之后的token要删除,不允许重复使用 3.3 取出的数据需要验证是否有效期内,并验证签名是否正确 4、解决了哪些问题 4.1 没有通过get传输私密数据 4.2 浏览器没有发起post请求,因此不存在后退刷新的问题 4.3 私密数据通过服务器间的post请求,因此对用户抓包,并不能获取到这份私密数据 抓更原始的包那就没办法,虽然不知道原始数据,但还是能登陆到用户账户上 5、导致的问题及解决办法 5.1 比之前多了一次http请求,会变的更慢 在相应的服务器端加host,降低解析时间(同一机房,走内网) 服务端只做数据存储到内存,不做额外操作降低运行时间 客户端设置超时,防止卡住 5.2 memcache存储的数据,存在一定几率丢失 可以暂时不考虑,概率太低,而且最坏的影响也就是用户某一次可能登陆不上(只有新用户) 5.3 token丢失或被抓包 32位的加盐散列,基本可以不考虑被暴力强刷 token即使丢失,问题也不大,因为token生成之后,用户基本上马上就使用,之后token就失效了
使用范例见附件:build_query
Apidoc的安装及使用
整 理:曹燕
时 间:2015-11-27
说 明:Apidoc的安装及使用(官方文档:http://apidocjs.com/)
(3)@apiDescription——api方法的详细介绍
(5)@apiErrorExample——一个返回出错信息的示例
(13)@apiParamExample——接口参数的一个示例
(17)@apiSuccessExample——一个成功的返回信息的示例
npm install apidoc -g
apidoc -i myapp/ -o apidoc/ -t mytemplate/
-i 输入文件的目录,即项目文件夹
-o 输出目录,即放置生成文档的位置
-t 使用的模板,会有默认的模板,当然也可以用自己定义的模板
示例: apidoc -i abc/ -o doc/ ![]()
放在你的工程项目的根目录下,是对项目的概要介绍,包括标题、简要介绍、版本等。
{
"name": "育儿网",
"version": "1.0.0",
"description": "育儿API文档",
"title": "API文档",
"template": {
"withCompare": true,
"withGenerator": true
}
}
其中name、version、description都会被显示出来。
/**
* @api {get} /user/:id Request User information
* @apiName GetUser
* @apiGroup User
*/
- 注释块必须用/** */包围
- @api {get} /user/:id Request User information
注释块必须以@api开头,否则会忽视这个注释块
- @apiName必须是一个独一无二的名字
- @apiGroup的作用是给这个方法分组
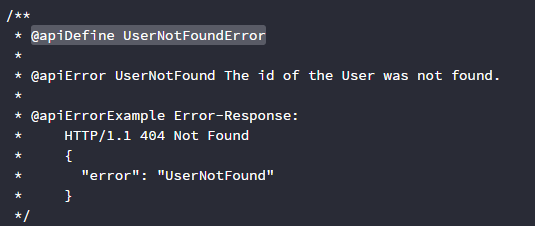
@apiDefine定义了一个可重用的块,然后其他块调用这个块的时候就写:
@apiUse UserNotFoundError
在生成的文档中会自动填充成UserNotFoundError块的具体内容。
Apidoc中的继承只能继承一层,层数多了会影响可读性。
【开头必需,除非是@apiDefine开头】![]()
Method:必须,方法的请求方式,如get、post、put、delete...
Path:必须,请求路径
Title:可选,可选,用于导航和文章的子标题![]()

Name:必须,独一无二的名字,之后引用这个块就是用这个名字
Title:可选,标题
Description:可选,详细介绍,另起一行写
(3)@apiDescription——api方法的详细介绍![]()
Text:必须,api方法的文字介绍
(Group):可选,有了group值之后该错误会被分组;默认归类为Error 4xx。
{Type}:可选,返回类型,如{Boolean},{Number},{String}等。
Field:必须,返回标识符,例如错误码。
Description:可选,对错误码的描述。![]()
(5)@apiErrorExample——一个返回出错信息的示例
会以预格式化代码输出到页面
{type}:可选,返回信息的格式
Title:可选,这个出错信息的标题
Example:必须,具体的返回信息
会以预格式化代码输出到页面![]()
{type}:可选,代码的语言
Title:必须,这个例子的标题
Example:必须,使用接口的代码![]()
Name:必须,分类的名称![]()
暂略
暂略
将这句放在块的起始位置,这样进行转换的时候这个块就会被跳过,常常用于一个块还没有开发完毕的时候。
Hint:可选,描述为什么不转换这个块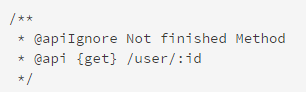
Name:必须,接口的名称,必须是独一无二的名称(允许版本不同的同一名称)
(group):可选,所有的参数会被分到这个类里,如果不设置,就分到Parameter。
{type}:可选,参数的类型,如{String}等。
{type{size}}:可选,参数取值的详细信息,如
{number{100-999}}——参数必须是个100-999的数字
{string{2..5}}——参数必须是2-5个字符的字符串
{type=allowedValues}:可选,关于变量允许取值的信息,如
{string="small","huge"}——参数必须是包含”small”或”huge”的字符串
Field:必须,变量名,表示该参数对于接口是必须的
[field]:必须,变量名,表示该参数对于接口不是必须的
=defaultValue:可选,参数的默认取值
Description:可选,参数的描述![]()
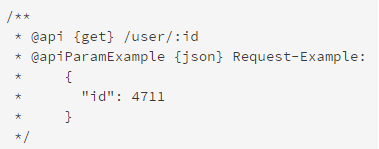
(13)@apiParamExample——接口参数的一个示例![]()
{type}:可选,请求信息的格式
Title:可选,示例的标题
{kind=link}
{kind=link}
暂略
(15)@apiSampleRequest——模拟请求时的url![]()
{kind=link}
{kind=link}
(group):可选,所有的参数会被分到这个类里,如果不设置,就分到Success 200。
{type}:可选,参数的类型,如{String}等。
Field:必须,返回标识符。
Description:可选,成功码的描述。
(17)@apiSuccessExample——一个成功的返回信息的示例![]()
{type}:可选,返回信息的格式
Title:可选,示例的标题
Example:必须,返回的具体信息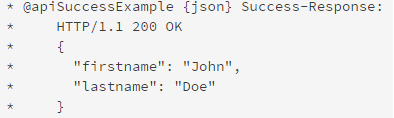
已经定义的块是指用@apiDefine定义的块![]()
Name:必须,@apiDefine定义的块的名称![]()
Group和name值都相同的块,可以进行不同版本的对比。可用于在生成的文档中和之前的版本进行比较,增加和修改的会用绿色标出、删除的会用红色标出。![]()
Version:必须,版本号![]()