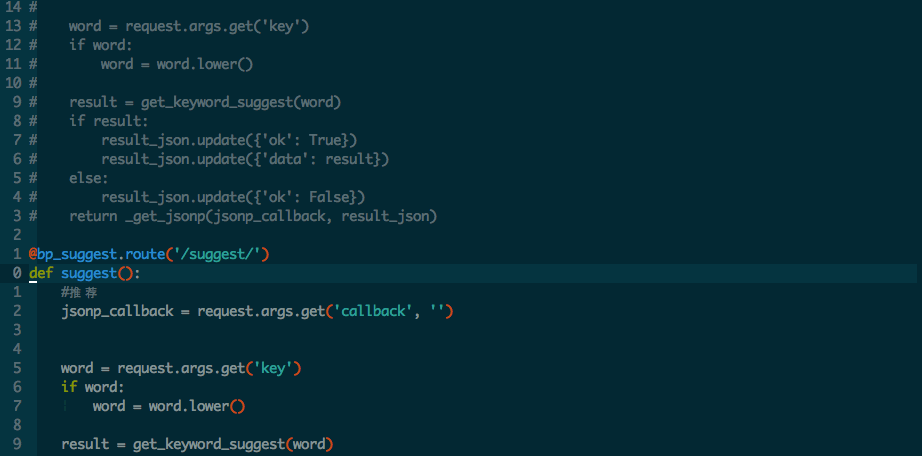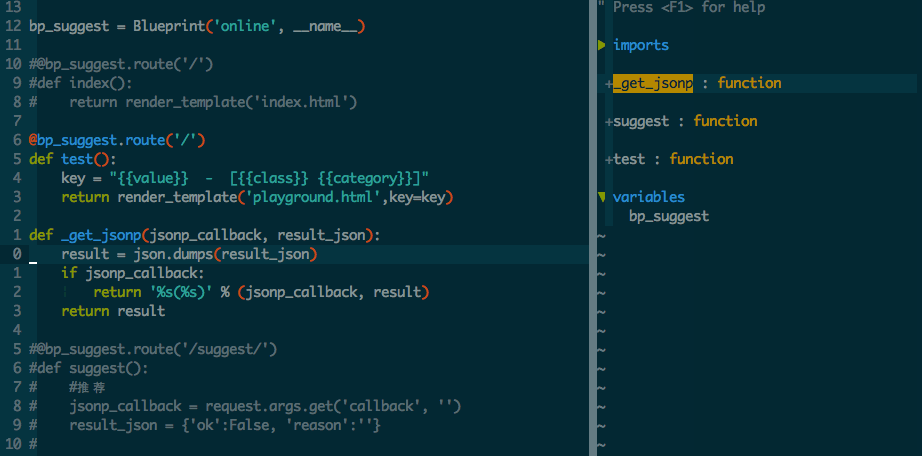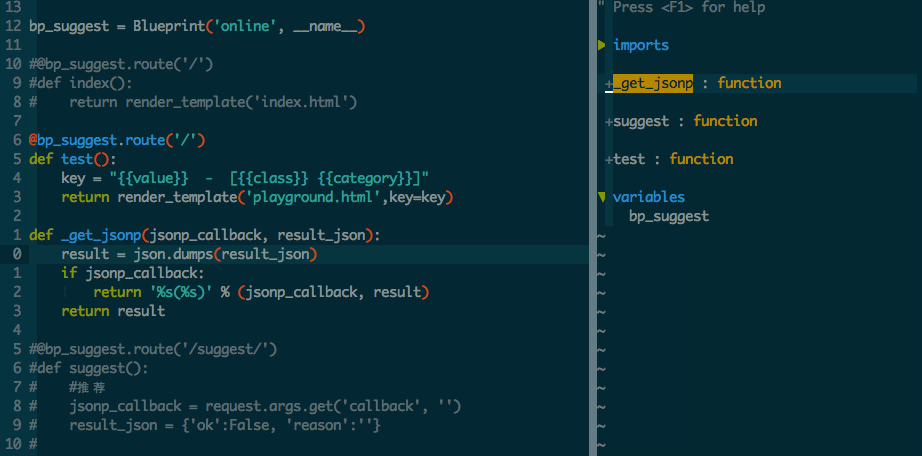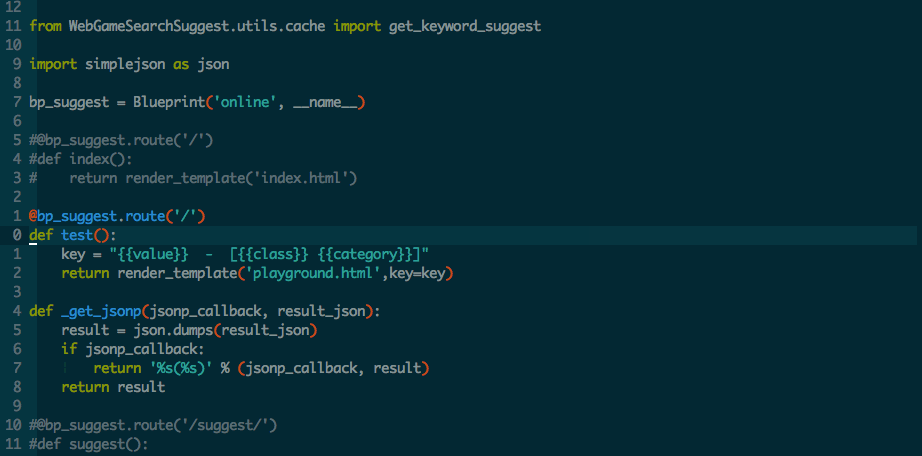
第一部分:了解solr
一、solr是什么?
Solr
二、lucene是什么?
Lucene
目前已经有很多应用程序的搜索功能是基于
三、Solr
Solr
第二部分:教程
一、从网站上下载
http://lucene.apache.org/solr/
我找的版本是5.3.1,最新版本是5.5
二、安装与运行
1、安装环境要求:
java的版本大于 1.7(利用java -version查看)
php接口是
2、启动:
bin/solr
默认是8983端口
http://localhost:8983/solr/


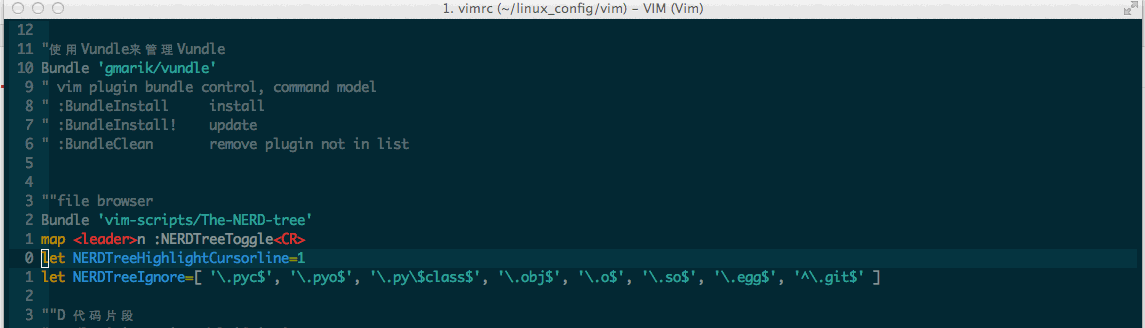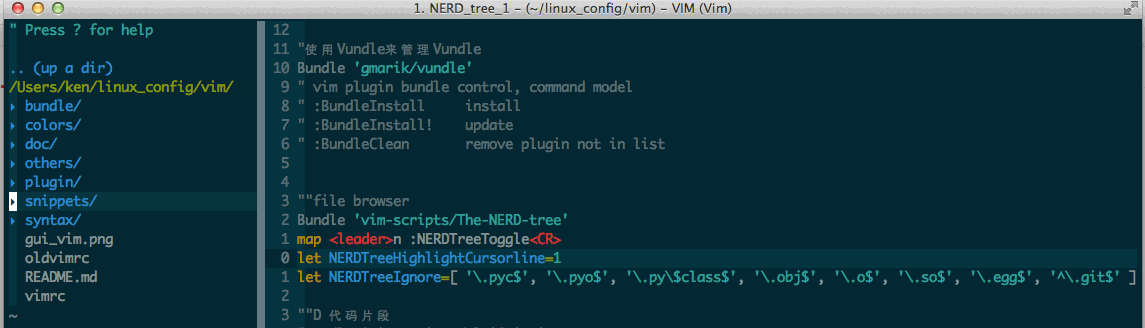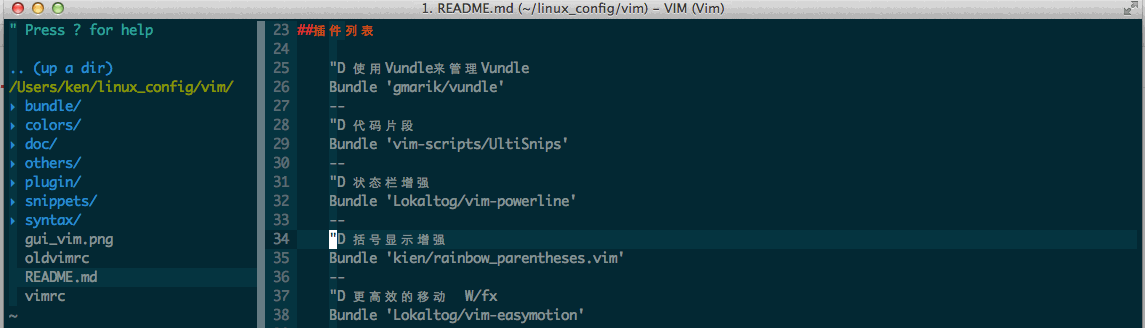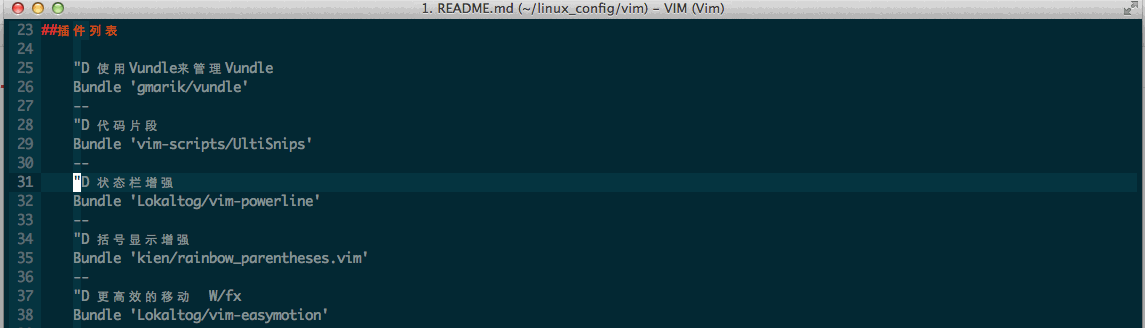
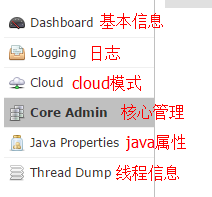
图片中各项的具体含义:
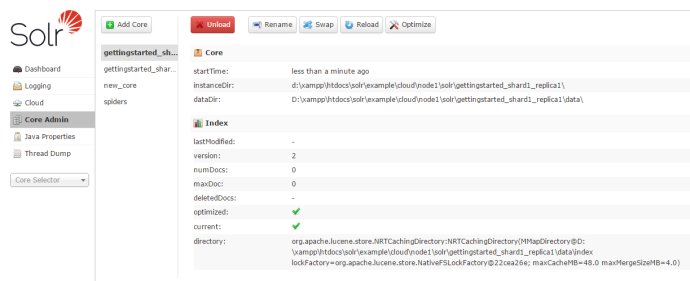
说明:这里是使用给好的例子,所以是有索引的。
使用
其他命令
bin/solr
bin/solr
bin/solr
三、建立一个实例:
bin/post 
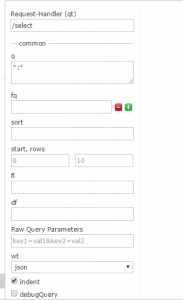
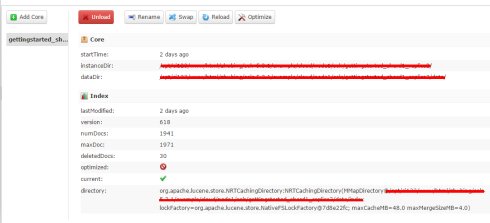
在界面中可以看到,建立了实例。
并且也是有数据的。
http://localhost:8983/solr/admin/cores?action=STATUS
四、数据说明:
1、数据类型:索引不同类型的文档
官方文档中说:
Solr
可以看出,可以建立不同形式的索引,包括json,xml,以及word
功能:添加,更新,删除等
如xml数据:
<add>
<doc>
<field name="id">USD</field>
<field name="name">One Dollar</field>
<field name="manu">Bank of America</field>
<field name="manu_id_s">boa</field>
<field name="cat">currency</field>
<field name="features">Coins and notes</field>
<field name="price_c">1,USD</field>
<field name="inStock">true</field>
</doc>
</add>
conf/schema.xml配置文件中规定好的。
五、怎么搜索?
1、界面搜索
http://localhost:8983/solr/#/gettingstarted_shard1_replica1/query
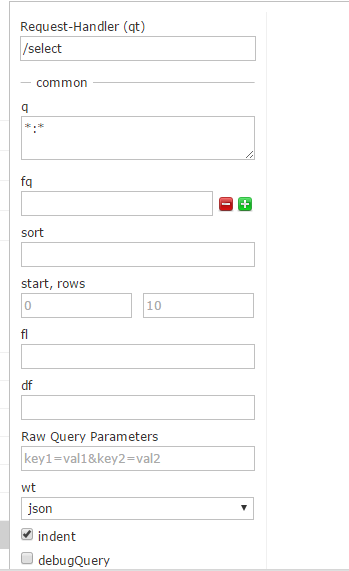
2、页面访问:
http://localhost:8983/solr/gettingstarted/select?wt=json&indent=true&q=foundation
六、思考:通过curl就可以获取,缺点就是不太安全吧?
如5.3上管理用户界面没有用户限制,所以任何人都可以访问管理员的用户界面将可以做任何事情与您的系统。
解决方案:基本认证和授权插件/设置防火墙
以上就是一个简单的索引的建立和搜索功能,有问题欢迎留言。